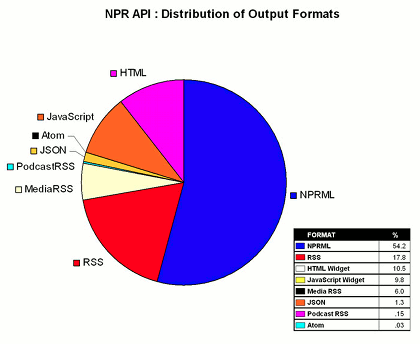
ProgrammableWeb : Why REST Keeps Me Up At Night
This post first appeared on ProgrammableWeb.com
With respect to Web APIs, the industry has clearly and emphatically landed on REST as the standard way to implement these services. And for good reason… REST, which is generally implemented as a one-size-fits-all solution, is an excellent choice for a most companies who wish to expose their content to third parties, mobile app developers, partners, internal teams, etc. There are many tomes about what REST is and how best to implement it, so I won’t go into detail here. But if I were to sum up the value proposition to these companies of the traditional REST solution, I would describe it as:
REST APIs are excellent at handling requests in a generic way, establishing a set of rules that allow a large number of known and unknown developers to easily consume the services that the API offers.
In this model, everyone knows how to behave and it can be incredibly powerful. The API providers establish a set of rules and the API consumers must adhere to those rules to get what they want from the API. It is perfect, right? In many cases, the answer is obviously yes. But in other cases, as our world scales and the number of ways for people to consume digital content and services continues to expand, this one-size-fits-all model is likely to fall short.
The potential shortcomings surface because this model assumes that a key goal of these APIs is to serve a large number of known and unknown developers. The more I talk to people about APIs, however, the clearer it is that public APIs are waning in popularity and business opportunity and that the internal use case is the wave of the future. There are books, articles and case studiescropping up almost daily supporting this view. And while my company, Netflix, may be an outlier because of the scale in which we operate, I believe that we are an interesting model of how things are evolving.
Netflix is currently available on over 800 different device types, including game consoles, mobile phones, TVs, Blu-ray players, tablets, computers, and almost any other device that can stream video. Our API alone handles more than two billion incoming requests on peak days, which translates into almost ten billion real-time outgoing requests from the API to internal dependency services. These numbers are up by about 70x from just two years ago. Most companies do not have that kind of scale, but it is clear that with the continued growth of the device market more companies are resetting their strategies to be less about the public API and more about internal consumption of their own APIs to support device proliferation. When this transition occurs, the API is no longer targeting “a large number of known and unknown developers.” Rather, the key audience is a small number of known developers.
The potential conflict between the internal and public use cases is in the design of the API itself. Keep in mind that the design implications will not be problematic in many scenarios. It becomes a potential problem if the breadth of devices becomes so wide that the variability of features across them becomes substantially harder to manage. It is the breadth of devices that creates a problem for the one-size-fits-all API solutions.
If your target is a small group of teams with whom you have close relationships, the dynamics around the API change. For Netflix, we persisted on the one-size-fits-all REST model for quite a while as more and more devices got added on top of the API. But given our scale, one thing has become increasingly obvious. Our REST API, while very capable of handling the requests from our devices in a generic way, is optimized for none of them. This is the case because our REST API focuses on resources that are meant to be granular representations of the data, from the perspective of the data. The granularity is exactly what allows the API to support a large number of known and unknown developers. Because it sets the rules for how to interface with the data, it also forces all of the developers to adhere to those rules. That means that each device potentially has to work a little harder (or sometimes a lot harder) to get the data needed to create great user experiences because devices are different from each other.
The differences across these devices can be varied and sometimes significant. Here are some examples of variances across devices that may be challenging for one-size-fits-all models:
- Different devices may have different memory capacity
- Some devices may require a unique or proprietary format or delivery method
- Some devices may perform better with a flatter or more hierarchical document model
- Different devices have different screen real estate sizes which may impact which data elements are needed
- Some devices may perform better having bits streamed across HTTP rather than delivered as a complete document
- Different devices allow for different user interaction models, which could influence the metadata fields, delivery method, interaction model, etc.
Just think about the differences between an iPhone and your TV and how they beg for different user experiences. Moreover, the XBox and the Wii, both of which project to the TV, are different in the way users interact with them as well as in the hardware constraints, both of which may require different APIs to support them. When considering more than 800 different device types, the variance across them becomes overwhelming. And as more manufacturers continue to innovate on these devices, the variance may only broaden.
- Small number of targeted API consumers is the top priority
- Very close relationships between these API consumers and the API team
- An increasing divergence of needs across the top priority API consumers
- Strong desire by the API consumers for more optimized interactions with the API
- High value proposition for the company providing the API to make these API consumers as effective as possible
If these ingredients are met, then you have the recipe for needing a new kind of API.
To solve this issue, it is becoming increasingly common for companies (including Netflix) to think about the interaction model in a different way. Rather than having the API create a set of rather rigid rules and forcing the various devices to follow them, companies are now thinking about ways to let the UI have more control in dictating what is needed from a service in support of their needs. Some are creating custom REST-based APIs to support a specific device or category of devices. Others are thinking about greater granularity in REST resources with more batching of calls. Some are creating orchestration layers, such as ql.io, in their API system to customize the interaction. These are all smart and practical ways around the problem. But with the growing number of devices, the increasing urge for companies to be on as many of them as possible, and the desire for continued innovation across these devices, these various solutions are still somewhat restricted. They are still forcing the developers to adhere to server-side rules and non-optimized payloads in an effort to have a one-size-fits-all solution. These approaches are closer to the flexibility needed in that they are not as rigid as the typical REST-based solution, but when supporting as many devices as Netflix does, we believe they fall short for us.
For Netflix, our goal is to take advantage of the differences of these devices rather than treating them generically. As a result, we are handing over the creation of the rules to the developers who consume the API rather than forcing them to adhere to a generic set of rules applied by the API team. In other words, we have created a platform for API development.