This presentation was for a meetup at Intuit on May 23, 2024
This presentation goes into detail on the key principles behind the Netflix API, including design, resiliency, scaling, and deployment. Among other things, I discuss our migration from our REST API to what we call our Experienced-Based API design. It also shares several of our open source efforts such as Zuul, Scryer, Hystrix, RxJava and the Simian Army.
This episode’s transcript is in progress; the partial transcript below has been auto-generated by Otter.ai.
Jeff Eaton: Hi, I’m Jeff Eaton, senior architect at Lullabot. And your host for insert content here. today I’m here with Daniel Jacobson, the illustrious Daniel Jacobson. He’s not necessarily someone that you may have seen him in content circles or nerding out in the CMS world that much, but he’s actually one of the movers and shakers.
His role for quite a few years was Director of Application Development at NPR, where he oversaw the development of COPE – the Create Once Publish Everywhere infrastructure that made all kinds of waves in the content strategy and CMS world. He’s the author of O’Reilly and Associates’ APIs: A Strategy Guide. And now, he’s the director of engineering for the Netflix API. So, he is just all over the place when it comes to content, APIs, and reusable structured content. It’s a pleasure to have you here, Daniel, thank you for joining us.
Daniel Jacobson: Thanks for having me, Jeff. Thanks for that very nice intro.
Jeff Eaton: Well, you know, it’s funny, I was actually we reading your blog a couple of weeks ago. And, you talked about a presentation that you had done at a conference on the architecture and you said, “wow”. You know, a bunch of people in the room knew about it and you know, they were familiar with it.
And it seems like you were almost a little startled by that. Did you expect the work that you were doing on that project to become such a big discussion topic,
Daniel Jacobson: You know, I really didn’t. We had been working — this goes back to the time of NPR — we’d been working on these concepts and implementation since 2002.
I can give you the history on that if you’re interested, but we were just doing what we thought was right. You know, thinking about architecture, thinking about longevity of application development and knowing that there are going to be a host of things that we’re not going to be aware of down the road, so trying to prepare for nimbleness.
So then in 2009, that’s when I first published that blog post on programmable web about COPE, I was just taking this step of, “okay, we’ve done all this stuff in the spirit of sharing, let’s share it”. And it was interesting to see how some people latched onto it.
But what really has surprised me is we’re in 2013, people are still talking about it. It’s mind boggling for me. And if you look at the blog post, over half of the, the comments were from 2012. I don’t know, 70 or 80 comments. so what’s really kind of staggering for me is the fact that, we published it in 2009.
We’ve been thinking of it for a number of years and implementing it for that time. But it’s still, or it is now resonating. It’s very weird.
Jeff Eaton: Well, I’ll back up for a second for anybody who might not be familiar, what is COPE? You know, what’s the idea behind it.
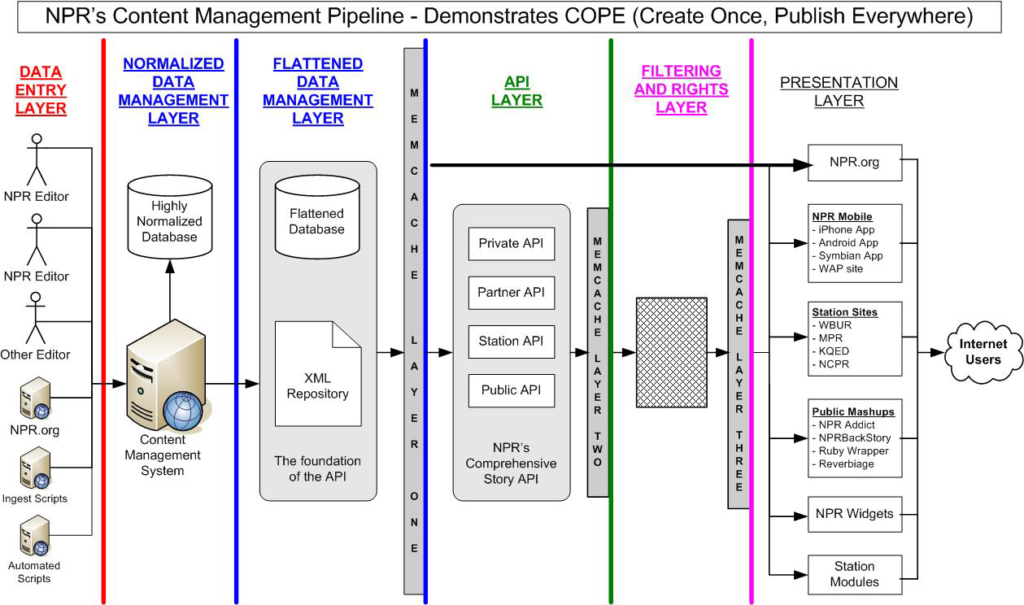
Daniel Jacobson: Okay. I’ll give you a little bit of a history on how we arrived at COPE and some of the sensibilities that went into it. COPE stands for Create Once Publish Everywhere. And the idea there is, you want to maximize the leverage of content creation and minimize the effort to distribute. The way that the whole thing really started, it goes back a little deeper. It was actually in 2002 when we had a series of different ways of publishing content to NPR. We had HTML files. We had a Cold Fusion system with a SQL Server database that publish very thin radio pieces to the web. Then I had build this other system, a Java based system with an Informix database to capture a little bit richer content and offer an opportunity for co-branding with local stations. In 2002, we looked at this and said, well, this is kind of a mess. We’re spending all this energy publishing in three different ways and we have three different presentation layers. What we really need to do is to collapse them into a system that really leverages our editorial time and gets us an opportunity to distribute to all these different places.
So interestingly, part of the story is that I pitched the idea with my boss at the time Robert Holt, who’s now at Microsoft. We pitched the idea to actually spend a bunch of time collapsing these systems and building an awesome system that takes care of all of this. At the time the VP, her name was MJ Bear, she wanted us to do due diligence and explore all these different avenues, content management systems like TeamSite and vignette, which are all quite expensive. So we did all that due diligence but I wasn’t convinced that that was the right route. And in fact, I knew we could do a better job by building it in house. The inflection point was that she quit. She left the job and, I basically said, “Great, let’s go build it. There’s no impediment anymore before things settle, let’s get this built before the next VP.” And, so we did that. We hunkered down and that’s where we really started thinking about the philosophies of “separate content from display” and, and “content modularity” and things like that.
So this was back in 2002 and it was partially driven by the idea that everything we’re doing here of collapsing these data systems, we’re also doing a redesign of the presentation layer. If we’re doing that, it’s highly likely that in the future, we’re going to have another presentation layer, either a new one to replace the old one or an additional one. And it’s almost like this keeps happening. It’s cyclical.
We need something great. so let’s throw out the old, and so we said, “all right, this presentation layer is going to go away too. So we really need a decoupling. And that’s where a lot of these COPE philosophies started to soak in. And actually we launched that CMS in November, 2002 and it’s still the centerpiece of NPR today.
Jeff Eaton: Holy cow.
Daniel Jacobson: Yeah, the CMS has lasted 10 or 11 years and we see that as a kind of success. So we take a lot of pride in that.
Jeff Eaton: It seems like that that decoupling that you talked about from a pure software development and architecture standpoint, that feels like the right thing to do, but you know what you mentioned the idea of teasing apart the core business assets that are content that gets created and managed over time from the changing sort of ephemeral presentation, teasing those things apart. It feels like it makes good business sense too. It’s not just about architectural purity. It’s a way to make sure that you don’t have to dig up the foundation every time the house needs to get painted.
Daniel Jacobson: Absolutely. And I will say it’s not without some costs because there were certainly some cultural battles that went into those discussions. An example that I can offer is when we were doing this design, what we intentionally said is that the story is the atom of the system. That was another philosophy of what we were doing. And so the atom the center of the NPR system universe. And we basically said the story is super thin. And generally speaking in NPR, people think of the story as being a radio piece. And we said, “no, radio pieces are not a necessary component of a story, it’s an enhancing and enriching part.” But so are images. So is text, so are pull quotes. So is whatever else you want to imagine that you want to put in there, but they’re not necessarily. The only parts that are necessary are basically the title, a unique ID, a date. And I think we said a teaser, that’s it. That’s all you need for a story.
Jeff Eaton: Interesting.
Daniel Jacobson: And from there, there’s a hierarchical data model. Tell me if I’m getting too geeky.
Jeff Eaton: Oh, this is the kind of stuff I love.
Daniel Jacobson: So we had hierchical data model where we basically had a story own what we called a “resource” and a resource was any enhancing component of a story. And a resource is generic. And then the sub hierarchy underneath that were the particulars, which would be text, images, videos, external links, internal references…
Jeff Eaton: transcripts, I think just went live a little while ago.
Daniel Jacobson: Transcripts is another one for sure. Those were all enhancing enriching components, but not necessary to have a story on the site. And I know that you and others on this podcast have talked about blobs and chunks. So, we, we tried to be very surgical with this idea, we wanted to have everything be its own entity. We don’t want these blobs of data. In fact, every paragraph in the text are stored separately and very distinct fields. We really thought about how we can manage this stuff in modular ways so, as you were saying, we’re teasing it out so that our business can gain value down the road.
And the controversial part is, especially in 2002, NPR is a journalism company focused on broadcast. Saying that the radio or the audio piece is not essential was pretty controversial. And it takes a little, it took a little massaging inside to get people to understand the power of this model. And it took actually a number of years to really get everybody on board.
Jeff Eaton: I would imagine that some of the decisions that you made earlier, like the story is central, even if every single story has a radio component for the first several years, there’s a stake in the ground, just in the nomenclature that you’ve been able to get in there.
Daniel Jacobson: Sure. you know, we really talked about stories and lists. Those were the two core concepts and you start talking about it and eventually that becomes part of the vernacular and part of the culture. And really, every story can belong to any number of lists, any number of types of lists. Lists are really just aggregating mechanisms. And that cut against the culture as well. And NPR, because you think about morning edition for March 13th, you think there’s a rundown, there are 15 stories for that day. That’s really just another list. And it’s not really a program. It is, it happens to be that this list’s name is Morning Edition…
Jeff Eaton: It’s a particular branded aggregation of stories, not necessarily this thing that is the primary means that people approach and find content, right?
Daniel Jacobson: It’s not a radio program anymore. It’s a list, and you know, you can identify it by titles. But you gotta think about it more generically and that’s when we started introducing a broader set of topics, such as “News”, “Music”, and things like that. And it really created, tremendous opportunity for NPR actually.
Jeff Eaton: There’ve been a couple of things that have been written about the actual longterm impact of it and what it’s allowed NPR to do in terms of turning around new products that are targeted at emerging devices or platforms without having to go through the same sort of just profound, painful rearchitecting of everything that a lot of other companies are having to do. Do you think that it’s interesting, do you think that this set up NPR for taking advantage of mobile, because of all the work that had already been in place.
Daniel Jacobson: Unquestionably, yes. Following the story of the content management system creation, I’ve talked a bunch about not building a web publishing tool. So, we felt like we were building a content management system and we thought about it in terms of having the content management editing tool be just another their presentation layer. And you can have any number of presentation layers. And so that actually gave a lot of freedom. If the editing tool is just one presentation layer and the website is one, we can have any number of these layers. We can just tack on new presentation layers, some of which have write capabilities and some don’t.
So as that started to mature a little bit back in 2004, RSS started to emerge. It was easy just to spin up another PHP file and have it render a RSS feeds and you pass in parameters and it’s going to yield a topic or a program. And then shortly after that, podcasting started to emerge and we can just easily float an MP3 file in the RSS feeds.
And, it was about 2007 when the NPR music site launched. We started to see the fact that we had this single point of failure, an Oracle database, which we were growing out of. We actually need a different data redundancy model. We needed a cluster of databases to be able to scale it. And NPR was a nonprofit, so we couldn’t afford a million Oracle’s servers. So, there were a couple of things that had me thinking that we needed another level of abstraction. And that’s when we introduced the API. That gave us an opportunity to basically put the NPR music development on a different trajectory, as well.
Now that everything is, or at least was, we were moving in the direction of having our sites fueled from the API. We can more easily abstract away the database underneath the API and swap in a cluster of MySQL servers, multiple databases. And, so we started thinking of the API in those terms. And then sometime after that, we opened it up publicly.
After we opened it up, we realized, “wow, we should be using that for other presentation layers like mobile sites and iPhones and iPads” and feeding into the Livio radio, radio devices that are feeding NPR content. Now it’s going into cars. So, all of this strategy, which started early in 2002, I think was in retrospect, we were lucky with having that kind of architecture.
It put us in a great position to just tack on more presentation layers and allow them all to feed off of one central distribution channel, which was the API.
Jeff Eaton: No, it definitely makes sense. I mean, although I think it is interesting that the real rise of mobile web traffic, especially apps, this idea is a given.
Businesses that have content might need this cluster of different ways that people can get to their stuff. I think it feels like that’s broken and a lot of existing sites and a lot of existing workflows and a lot of existing platforms that companies have built out. And I think that sort of corresponds to where the huge spike in interest in the work that’s been done on COPE, really took off because suddenly everyone was feeling just such a tremendous amount of pain around that issue.
What you’re describing is interesting because it’s not the same kind of story your team had been working on this for a long time based on deeper needs than simply we need to go mobile or something like that.
Daniel Jacobson: Yeah, that’s right. I think we were lucky to have had a series of challenges, like financial challenges, not being able to afford vignette. We were lucky and that we were doing a series of things all at once. And we knew that we were redesigning and we were likely to have to redesign again. There’s a confluence of things that got us thinking early about it. We had no idea the iPhone was going to go nuts. I mean, if we had that kind of foresight, I should have been betting on the stock.
But we were very lucky and I think we actually made a series of decent decisions thereafter that put us in a good position. When I hear about folks who have been, who weren’t quite as lucky to have that confluence of events and they have to go back and retrofit. Well, now the space is much more complicated and you’re already embedded in your web publishing tool. So their rearchitecture at that stage is actually much more expensive and much more painful. It just seems like we did it at the right time. Actually, things were very lucky.
Jeff Eaton: You mentioned that the actual editorial tools, the things that the actual content creation people use is just another presentation layer in that sort of approach. How did that side of things evolve? Cause you know, the structured content approach that you’re describing isn’t necessarily a natural fit or a natural transition for people who aren’t used to saying data modeling is their weekend hobby.
Daniel Jacobson: Data modeling is really at the center of it all. I felt it was critically essential to start with a very clean data model. That that was the starting point. How do we, how do we imagine this content to be stored and thinking about it in those very teased out ways? So yeah. Text is very different than a teaser, which is very different than images.
And everything was really isolated. That’s where the content modularity part comes in. So we, that’s where we started. And if you have that well, that’s just your data repository. And then any number of apps can hit against that. And we had the website hitting against that, but we also had this suite of tools that could write to it. They can also access it, but then we started, over time experimenting with areas of the website, writing different user related things to the database. Basically, it starts with the database. That’s all you have. And then every, everything else is either reading or writing or both to that database. And we just thought about it in those terms.
Jeff Eaton: Was the user experience aspects of building out those tools, something that you were involved with or was that something that there was a different team of people trying to make the tools usable for this way of approaching things.
Daniel Jacobson: Okay. So I’m actually really glad you brought that up because I kind of glossed over that. First I want to be clear and maybe this kind of gives people some hope. When you say the team of people, the total team that I can think of that executed on this entire CMS project back in 2002, it was about four people.
Jeff Eaton: Oh, this is like learning how bacon gets made.
Daniel Jacobson: Yeah. I hope I don’t disappoint anybody.
Jeff Eaton: I think that’ll encourage a lot of people actually.
Daniel Jacobson: Yeah. I mean, it really started with this massive document that I put together that we used for due diligence to send out the vendors per the VPs request.
So we had a vision that we kind of pieced together and that vision, both encompassed what the data structure’s going to look like, what’s it going to look like in terms of conceptually the CMS or the content capture part as well as, directions for the website. We obviously then brought it in house.
We didn’t have a VP anymore. It was me and one other backend developer at the time. And there was one front end developer and there was a designer. And then my boss, so that was the team. We had a suite of editorial folks who contributed meaningfully to this. I don’t want to discount them, but in terms of the engineering, that was it.
So me and the other backend engineer, we wrote all the tools around the content management system. But before we did that, we were heavily informed by the designer. And I was pretty involved in this as well. We did a series of usability tests. We took data from both the usage patterns of our users online and the npr.org users. We took information about the three discreet ways that we publish. We had the Cold Fusion system, that Java system, the HTML files.
What are the kinds of things we’re building? We knew that actually, in the mode right now, at that moment too, we had a very limited sets of assets. It was very audio focused, but we knew that things coming down the road were going to be much more expansive in terms of the available assets: images were probably to come later, and full text. And we were hiring editors too on the online side specifically to build out those stories.
So we were informed by all of those things and did a whole series of mockups and clickable prototypes for the editors and sat down with them and said, “okay, well, what do you think of this? What do you think of that?” And then here’s the interesting part. We took all that data and we had to discount fair amount of it because we thought that they were still thinking about it too much like NPR, right?
Jeff Eaton: Yeah. They were thinking, “Oh, you’re building the new version of what we’re used to.”
Daniel Jacobson: Yes. Right. So, we took on all of that. There were a lot of really great ideas and fundamental things that drove the direction of where we’re going. But again, we had to think, we’re thinking bigger than this. We’re thinking there will be another design, there’s this and that.
So, we needed to discount a portion of our learnings. And, yeah, so all of that kind of boiled into the content management system. And I think you and Karen have talked about this fair amount, that you can’t just build tools as an engineer would build a tool, right? You’re building your website to have it be meaningfully useful to the website user.
You need the same mindset when you’re building the CMS. You want it to be infused with the sensibilities that will make them effective at what they’re doing. So we tried to take all those sensibilities and make something that they would succeed with, and evolve it over time.
Jeff Eaton: Especially with sites that have an existing infrastructure and stuff like that. It’s very easy to see those kinds of things. And imagine it’s just insurmountable, there’s definitely a lot of hurdles, especially, it feels like every year that passes there’s more weight that’s being put on a lot of the web properties, the different companies, but the idea is it doesn’t necessarily take an army to do this. It seems like it’s more of a wheel inside of the organization to take this kind of path.
Daniel Jacobson: Yeah. I have a couple of thoughts on that. First, generally I agree. I think the one area I would disagree is that the world is different now than 10 years ago. And I think, again, we were lucky to have gone down that route at the time that we did, because like you said, the weight is lighter in 2002 than in 2013. But in every other capacity, I agree. And you need to have commitment, and the commitment not only starts with the commitment to vision, but resourcing it appropriately. If you need these engineers to build this out, hire engineers, and I’m a big believer in the idea that excellent engineers are going to be, some people say, 10 times more effective than average engineers. So having really smart people who are able to execute on these things, you can really tease out what you’re going for. What’s the best way to execute on it? That’s going to pay way more dividends than just hiring a bunch of people and throwing money at it.
Jeff Eaton: What you were describing earlier was it was a very cross functional team, all working on these things. You were talking about working in close conjunction with the designers who are planning out what the new visual appearance of the site was going to be in how it was going to operate, working with the the content creators and the editorial team.
It wasn’t just a matter of wireframes that were thrown over the wall and you guys implemented it, which I think is one of the hardest scenarios for a lot of people who build an implement to find themselves in these days.
Daniel Jacobson: Yeah. It was kind of a scrum before scrum started taking off. I mean, that’s basically what it was. The only way it could have succeeded was very close collaboration with everybody on board with the message.
Jeff Eaton: So I guess coming back to that initial question, is it a little weird now to hear the stuff that you worked on turned into sort of the GoTo example slide in everyone’s presentations about structured content and reuse?
Daniel Jacobson: Yeah. It still freaks me out. It’s great. I love seeing it. I love talking to people about it and if there’s a way that I can help people, I love doing that. It is still a little surreal too, however, as I haven’t even been at NPR for the last two and a half years. And, so it’s interesting to still see it coming through the tweet stream once in a while.
Jeff Eaton: I can imagine. Well, you mentioned that you’re now at Netflix actually, and you’re the director of engineering for the Netflix API. How is that different? I mean, it seems like it’s an API and it deals with content, but it is really a big shift.
Daniel Jacobson: Yeah. It’s a huge shift in certain categories and it’s actually quite similar in others. The similarities are, we’re both media companies. But actually Netflix considers ourselves technology, company in media. I think NPR should be striving, if they are not already, for the same thing, as a technology company producing content for distribution, trying to get on multiple devices, reaching consumers with rich multimedia experiences.
Those kinds of things are similar. The scale. is fundamentally different. NPR, I think is a reasonably decent scale operation. but again, by the time I left it, my team was, including some contractors, around 20, I think. Here the engineering team is about 600.
The scale of the APIs: I think the NPR API is however many millions of requests a day. Maybe it’s a hundred, maybe it’s 50. I don’t remember the exact number. The API here does two and a half billion transactions a day. So what goes into those problems, you know, solving those problems? It’s a fundamentally different approach. And so contextually at NPR, it was even when I left, it was basically one team broken down into different groups, but focused on one pipeline and that pipeline was pretty interconnected. So, you have the content management system that publishes into a cluster of databases and the cluster of databases draw from an API, and the API distributes out to any number of destinations. The NPR engineering team was building pretty much all of that.
Jeff Eaton: Wow. 20 people or so!
Daniel Jacobson: Here it’s highly distributed. It’s an SOA model. lots of engineering teams focusing on specialized tasks. And my team does not really store any data. We don’t really have any editorial tools or anything like that. We’re basically a broker that takes data from other people’s systems and pass it across HTTP over to devices and people. So the core responsibilities for this team is making sure that we have a solid distribution pipe, scaling the system effectively with the growth of the company and growth of the system and ensuring resiliency. Those are the three key responsibilities I played out for the team. Whereas NPR, it’s building a lot of features and presentation layers, or managing a CMS.
So yeah, the scale I think is really at the core fundamentally different, and that drives a lot of the differences in other categories.
Jeff Eaton: Yeah. I think, at Netflix, you guys are responsible for what I think a double digit percentage of evening internet traffic or something, something like that.
Daniel Jacobson: Yeah. It’s 33%, right?
Jeff Eaton: That’s definitely a statistic. Not many people could claim.
Daniel Jacobson: I mean, there are all kinds of different ways that Netflix has massive scale. That’s one of them. The two and a half billion transactions a day, but we’re also an 800 different device types. It’s kind of mind boggling. When you think about some of these numbers.
Jeff Eaton: I am just blown away that there are that many kinds of devices to be on. I mean, I guess it makes sense, but it’s just, it is staggering.
When you think about that the device proliferation that we’re seeing, is it really difficult to keep up with it?
Daniel Jacobson: Yeah. And the scary part is it’s not done. Your fridge is going to have a screen on it. Why not have Netflix there? Right. Basically this is the beginning of it, actually, in my view.
Jeff Eaton: So how has it been, how has it been different? Just philosophically, like at NPR? I think a lot of the case for the API is about very public distribution of a lot of different information. But with Netflix, it’s different, it’s basically you’re API is part of a tool chain that allows you to provide a particular service to customers.
Are there ripple effect differences in how the two get approached?
Daniel Jacobson: I actually think you’ve mischaracterized NPR a little bit. Even by the time I left, I was starting to position it differently and I think that’s still the case. So, Javaun Moradi, he’s the PM there now for the API and the rest of the folks there. I think they focus intently on internal consumption. They still have the public API and still use it as a distribution mechanism to the member stations, among other things. But an overwhelming percentage of the traffic to the API is from NPR properties. It’s not from the general public domain. and then the next category would be the stations, and then the general public.
So I think in that regard, it’s very similar to Netflix. now that the percentages and the numbers are very different. So I think whatever their percentage is, 60, 70% at NPR. For Netflix, 99.9 plus percent of the traffic is from Netflix-ready devices. And we still have a public API, but that’s sees an incredibly small percentage of the traffic
Jeff Eaton: Then, I guess that is sort of a perception thing then. I mean, I’ve always heard a lot about the context of the public open API being there. And that’s actually a question that I think a lot of people have as well, “if my business doesn’t make sense for putting out a giant fire hose of all of my stuff to the world, how can I really leverage this stuff?” And I think that that’s part of it. You don’t have to think about it as just the all you can eat buffet of our stuff. It can be used for internal purposes too.
Daniel Jacobson: Yeah. I’d go a step further and I’d say it’s the majority. In fact, the overwhelming majority of value from API use will be the internal consumption. and this is from my background at NPR and at Netflix, but also in talking to a lot of people in the space.
I see other companies like Evernote and The Guardian and The New York Times. They all have similar pie charts where the overwhelming consumption is internal. So I actually think that we are seeing a shift in the marketplace towards internal consumption. People are looking at their businesses differently.
It’s like, how can we get on all these different devices? Let’s not worry as much about trying to piggyback on developers in their free time in their garage. And let’s dedicate our resources to building these things on our own. How do we get there? Let’s build an API so we can leverage the distribution rather than building one-offs all the time for either individuals, developers who are looking at dealing with the massive explosion of devices and channels.
Jeff Eaton: What would, what kind of advice would you have for them? What kind of major pitfalls would you tell them to steer clear of?
Daniel Jacobson: Well, definitely steer clear of lots of one-off development and steer clear of thinking, depending on who you are and what your business is, steer clear thinking of yourself as not being a software company.
I think that’s, to me, that’s the number one thing. If you can re-imagine whatever your business is and think of yourself as being a technology company, or at least partially a technology company, then you’re going to dedicate the resources to that. And if you’re dedicating resources to that, then you’re gonna have smart people who are thinking about these problems in the right way.
And I don’t think there’s a one size fits all approach for everybody, but I think if you have good people thinking about it, you’re going to end up with highly leverageable content management or distribution channels. You’re going to end up being much more nimble than you were otherwise.
So it’s probably sidestepping your question, but, I don’t know how else to say it because even at Netflix, we have very clearly stepped away from trying to be one size fits all for reaching all of the platforms we’re hitting.
Our REST API used to be a one size fits all model that we use for quite a while, and it felt like the right thing to do. But my view on that is that the API is a tool and when that tool runs its course, we need to move on to something that has greater pragmatic value. So I wouldn’t be beholden to any given technology. I’d be beholden to smart technologists who you trust to make good decisions.
Jeff Eaton: And it sounds like an important part of that is having a really clear coherent grasp of what it is that you’re trying to accomplish and what the longterm goals are too.
Daniel Jacobson: Absolutely. Yep. That goes right in with the commitment. If you’re committed to this, then think about how this is going to play out in five years and start planning for that.
Jeff Eaton: Well, I want to say thank you very much for joining us. it’s been a pleasure and, I hope that we’ll cross paths again in the future.
Daniel Jacobson: Absolutely. Thanks a lot, Jeff. I really appreciate it. And yeah, definitely.
Jeff Eaton: Thanks for listening to insert content here. If you’d like to catch up on our archives or keep up on our new episodes, visit us at dot com slash ideas slash podcasts slash insert content queue.
Extra Story: Daniel Jacobson: Me and another NPR engineer, when we were doing a modeling exercise, we really got caught up on what to call the story, the atom of the content management system, in the database. And we debated about this for way too long. And her stance was let’s call it “page”, as in a web page or some page representation. And I wanted nothing to do with that because I thought that was too bound to a given presentation layer concept. I really wanted something way more generic. So I started throwing out ideas like “object” or something that really didn’t have a whole lot of meaning, but was abstract.
Jeff Eaton: Totally abstract.
Daniel Jacobson: Exactly. Yeah. And we went around this debate time and time again, and ultimately what we decided on was “thing”. So the central table in the system, and I think it still is the case today is called “thing”. We did that specifically so that we could not be worried about if a story going to end up on a mobile app or on an IP radio, which don’t really have a concept of “page”. It’s just, here’s this “thing”, we’re distributing it out and that’s it.
Last Friday (February 8th), I spoke at the Intelligent Content Conference 2013. When Scott Abel (aka The Content Wrangler) first contacted me to speak at the event, he asked me to speak about my content management and distribution experiences from both NPR and Netflix. The two experiences seemed to him to be an interesting blend for the conference. And when I got to the conference, I was absolutely floored by the number of people who had already heard about NPR’s COPE model!
I have to admit, it had been a while since I last thought that much about the NPR days, but doing so brought back a lot of interesting memories. When more deeply considering those experiences alongside my Netflix experience, I was able to see commonalities in practice, philosophy, execution and results (although at different scales).
At any rate, embedded below are the slides from my presentation. I spent a good chunk of time commenting each slide as my presentations tend to be very image-heavy, which often results in lost context. The comments have added that context back in.
Thanks again, Scott, for having me at the conference. And thanks to all of the attendees with whom I spoke before and after my talk. The event was a lot of fun!
On February 8, 2013, I spoke at the Intelligent Content Conference 2013. When Scott Abel (aka The Content Wrangler) first contacted me to speak at the event, he asked me to speak about my content management and distribution experiences from both NPR and Netflix. The two experiences seemed to him to be an interesting blend for the conference. These are the slides from that presentation.
I have applied comments to every slide in this presentation to include the context that I otherwise provided verbally during the talk.
I originally published this article to ProgrammableWeb.com on December 10, 2012
The purpose of a content API is to make the content available to its audience in the most useful and efficient way possible. To be a useful API, it needs to help the developers make their jobs easier. This could mean a wide range of things, including making it easier to dig into the API, allowing for greater flexibility in the responses, improved performance and efficiency for both the API and its consumer. Below are seven development techniques (all of which are part of the NPR API) that can help content providers improve the usefulness and efficiency of their APIs on both sides of the track. These techniques played a critical role in the success of the API which now delivers over 700 million stories per month to its users (more stats on the NPR API coming soon on our Inside NPR.org blog).
Be Flexible: Support Multiple Output Formats
Making the API as available and accessible as possible is very important in drawing developers to use it. So providing the content in a range of formats will increase the likelihood that the developer can rely on existing libraries and make as few changes to the code as possible.
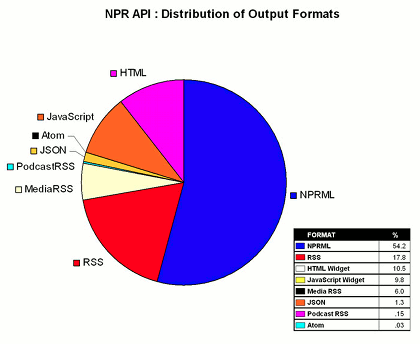
The NPR API offers eight different output formats in an effort to improve efficiency for the developers. Above is a graph demonstrating the distribution of requests for each of the formats in July of 2009. As you can see, the majority of requests are to our proprietary XML markup (NPRML). That also means that almost 50% of the requests, or about 20M requests per month, use the other seven formats. In offering offering these other non-proprietary XML formats, the API is able to support developers that may have existing applications that pull in content in one of these standardized format, such as MediaRSS or Atom.
To make it even easier for people to use the API, NPR also launched with JavaScript and HTML “widgets”. The other six formats require more sophistication in order to put the content in an application or website. The widgets, however, are pre-designed feeds of NPR content (based on the developer’s selections) that can be easily dropped into a page.
Be Efficient: Handle Partial Response
This concept is now starting to get some more traction, now that Google announced partial response handling for some of their APIs. NPR’s API also makes extensive us of this feature because it really is tremendously valuable to the provider and the consumer of the API. For example, NPR stories contain a wide variety of fields and assets in the API. If the consumer is forced to handle the complete document, even if they only want a few fields, they have to endure all of the latency issues from the API itself as well as the additional processing power needed to handle the undesired fields.
As a result, NPR incorporated a “fields” parameter (the same parameter name used by Google) that can be used in the query string to limit the resulting document to only the fields of interest. This approach creates documents that are smaller and much more efficient. Overwhelmingly, more requests to the NPR API contain the fields parameter than those that do not (in fact, it isn’t even close).
Here are a few examples of how the same query to the NPR API, returning the same stories, delivers different documents based on the fields parameter (you will need to register for your own NPR API key to execute these queries):
An extension of partial response is to allow the developer to specify the number of items they would like in return. Some APIs return a fixed number of results, which can bloat the document just like the extra fields can. The NPR API, to counter this, allows the developer to pass in the number of results desired (with a fixed ceiling for any given request). To dig deeper in the results, we incorporated a “pagination” feature in the API. Here are some examples of how to control the number of stories:
Give Them Control: Allow for Customizable Output Markup (“Remapping Fields”)
As mentioned in the transform section, if the API can easily serve existing applications that expect specific markup, it potentially increases adoption and improves developer efficiency. To extend that functionality, the NPR API offers a function that we call “Remap” which essentially lets the developer modify the name of one or more XML elements or attributes in the output at request time. This is done in the query string and the API transforms the markup accordingly in real-time. Here are a few examples:
In this example, the remap parameter changes the story title to < specialTitle >:
Another benefit to remap (which we have fortunately not had to use) is that it can be used to handle backward compatibility as the API grows and changes. NPR’s philosophy is to make sure that upgrades do not adversely affect existing functionality. That said, if an element or attribute does need to change, we could execute apache rewrites for all old API calls and have the remap function applied to have the output match that of the old markup. Alternatively, the developer could simply modify their API call instead of having to change their codebase to match the markup changes. (Although we do not intend to change existing markup, if we do, we would advise developers to upgrade their code accordingly. That said, rather than having the applications fail during the transition, remap could be used to temporarily handle requests until the full codebase can be upgraded).
Be Fast: Set Up a Comprehensive Caching Architecture
Performance is another critical aspect of APIs when it comes to enticing developers to use them. After all, if the API is sluggish, developers may not want to depend their application on it.
Smart caching of queries and results can really improve the speed of the system. NPR has implemented several layers of caching for the API, as follows:
Base XML – Caching the full document for each item is important to prevent the system from executing disk I/O before doing any transform. We cache the Base XML first in memory and secondarily as XML files to eliminate the need to access our content database.
Full Query Results – When compiling the list of items to be returned for any given story, it is important to cache the full list because popular applications that have many concurrent users (such as NPR Addict) are very likely to execute the same queries and expect the same results. The cached result is a single document containing the full list of all items and the full base XML for each.
Transformed Query Results – The calling application, such as NPR Addict, expects the document to be transformed to fit the application’s needs. So, the results that get cached in Full Query Results may get transformed to MediaRSS while simultaneously removing extraneous fields. Caching the final results that get returned to the calling application enable fastest performance without compromising the system’s ability to use the other caching layers to produce different versions of the document.
Give Them Tools: Provide a Query UI with the Documentation There are two truths about developers and documentation: the former always expects the latter, but seldom uses it. Of course, you cannot have an API without providing comprehensive documentation. That said, offering a simple user interface that helps developers get what they need from the API wil increase adoption and make life easier for them.
NPR’s API launched with a tool that we call the Query Generator. This tool exposes more than 6500 query-able IDs, methods for controlling the output format, fields to be returned, date and search restrictions, pagination, and more. Using the interface, the developer can select their options and have the tool create the query string for their API request. The developer can also see the results of that query inline before commiting it to their application. Almost exclusively, developers (including the NPR staff) use this tool to create queries, rather than reading the documentation.
Be Open: Eliminate Rate Limiting
Throttling or limiting access to APIs is an inherent disincentive for developers. Moreover, it is actually a detriment to the API provider. After all, the purpose of the API is to grant access to the content. If a given developer can only call the API 5000 times a day, and that developer creates a hugely popular application, the rate-limiting will inherently stifle the developer and the viral nature of the API.
Granted, most APIs use rate-limiting or tiered access levels to allow business people to control the graduation of API users. This seems counter-productive to me though. The better approach is to open access completely, identify those incredibly successful usages, then work with the developer accordingly on a mutually beneficial relationship. This way, applications are given full ability to grow and mature without arbitrary constraints.
Other APIs implement rate-limiting to protect the servers from unexpectedly high load. This is a legitimate risk which, if encountered, can adversely affect the performance of all users. That said, building complicated features into the system, such as rate-limiting, can be much more costly than configuring a scalable server architecture. Moreover, each request to the API will see slight latency increases as a result of the rate-limiting analysis. I know that latency is marginal, but why introduce any additional latency, especially when creating disincentives for developers?
Be Agile: Practice Iterative Development
Building your API over time has several benefits. First, it signals to the developer community that this API is meaningful to the provider and will continue to grow and get supported over time. This sounds trivial, but it is a very important part of the relationship with the community. If developers are not sure about your commitment to the API, are they likely to spend their own time building an application around it?
Another benefit of iterative development is that you do not have to get the API perfect the first time. I will qualify that by saying that, as a matter of principle, any release for an API should be done with the expectation that it will be supported for a long time. This is important because changes to existing API features will break the applications of those that use them. When I say the API doesn’t have to be perfect, I mean it does not have to be complete. New features can (and should) be added over time, extending its capability and making it more attractive for potential developers.
To put it another way, you will not have every detail of the API solved at the initial launch. It is much better to go live with the features that you know well while deferring those that you do not. Trying to cram in tenuous requirements will create headaches for you and for the community down the road. Spend the time necessary on figuring out the features, the supporting markup, the access and error methods, etc. before you commit to an API feature.