The digital media world is in the process of dramatic change. For years, the Internet has been about web sites and browser-based experiences, and the systems that drove those sites generally matched those experiences. But now, the portable world is upon us and it is formidable. With the growing need and ability to be portable comes tremendous opportunity for content providers. But it also requires substantial changes to their thinking and their systems. It requires distribution platforms, API’s and other ways to get the content to where it needs to be. But having an API is not enough. In order for content providers to take full advantage of these new platforms, they will need to, first and foremost, embrace one simple philosophy: COPE (Create Once, Publish Everywhere).
The diagram above represents NPR’s content management pipeline and how it embraces these COPE principles. The basic principle is to have content producers and ingestion scripts funnel content into a single system (or series of closely tied systems). Once there, the distribution of all content can be handled identically, regardless of content type or its destinations
COPE Through COPE, our systems have enabled incredible growth despite having a small staff and limited resources. Although the CMS is home-grown, COPE itself is agnostic as to the build or buy/integrate decision. Any system that adheres to these principles, whether it is a COTS product, home-grown, or anything in between, will see the benefits of content modularity and portability.
In this series of posts, I will be discussing these philosophies, as well as how NPR applied them and how we were able to do so much with so little (including our NPR API).
COPE is really a combination of several other closely related sub-philosophies, including:
Build content management systems (CMS), not web publishing tools (WPT)
Separate content from display
Ensure content modularity
Ensure content portability
These philosophies have a direct impact on API and distribution strategies as well. Creating an API on top of a COPE-less system will distribute the content, but there is still no guarantee that the content can actually live on any platform. COPE is dependent on these other philosophies to ensure that the content is truly portable.
Build CMS, not WPT COPE is the key difference between content management systems and web publishing tools, although these terms are often used interchangeably in our industry. The goal of any CMS should be to gather enough information to present the content on any platform, in any presentation, at any time. WPT’s capture content with the primary purpose of publishing web pages. As a result, they tend to manage the content in ways focused on delivering it to the web. Plug-ins are often available for distribution to other platforms, but applying tools on top of the native functions to manipulate the content for alternate destinations makes the system inherently unscalable. That is, for each new platform, WPT’s will need a new plug-in to tailor the presentation markup to that platform. CMS’s, on the other hand, store the content cleanly, enabling the presentation layers to worry about how to display the content not on how to transform the markup embedded within it.
True CMS’s are really just content capturing tools that are completely agnostic as to how or where the content will be viewed, whether it is a web page, mobile app, TV or radio display, etc. Additionally, platforms that don’t yet exist are able to be served by a true CMS in ways that WPT’s may not be able to (even with plug-ins). By applying COPE, NPR was able to quickly jump on advancements throughout the years like RSS, Podcasts, API’s and mobile platforms with relative ease. As an example, the public API took only about two developer months to create, and most of that time was spent on user and rights management.
This presentation shows the same NPR story displayed in a wide range of platforms. The content, through the principles of COPE, is pushed out to all of these destinations through the NPR API. Each destination, meanwhile, uses the appropriate content for that presentation layer.
Separate Content from Display Separating content from display is one of the key concepts supporting COPE. In the most basic form, this means that the presentation layer needs to be a series of templates that know how to pull in the content from the repository. This enables the presentation layer to care about how the content will look while the content can be display-agnostic, allowing it to appear on a web site, a mobile device, etc.
But to truly separate content from display, the content repository needs to also avoid storing “dirty” content. Dirty content is content that contains any presentation layer information embedded in it, including HTML, XML, character encodings, microformats, and any other markup or rich formatting information. This separation is achieved by the two other principles, content modularity and content portability
At a high level, many systems and organizations are applying the basics of COPE. They are able to distribute content to different platforms, separate content from display, etc. But to take some of these systems to the next level, enabling them to scale and adapt to our changing landscape, they will need to focus more on content modularity and portability. In my next post, I will go into more detail about NPR’s approach to content modularity and why our approach is more than just data normalization.
As I discussed in my recent blog post on ProgrammableWeb.com, Netflix has found substantial limitations in the traditional one-size-fits-all (OSFA) REST API approach. As a result, we have moved to a new, fully customizable API. The basis for our decision is that Netflix’s streaming service is available on more than 800 different device types, almost all of which receive their content from our private APIs. In our experience, we have realized that supporting these myriad device types with an OSFA API, while successful, is not optimal for the API team, the UI teams or Netflix streaming customers. And given that the key audiences for the API are a small group of known developers to which the API team is very close (i.e., mostly internal Netflix UI development teams), we have evolved our API into a platform for API development. Supporting this platform are a few key philosophies, each of which is instrumental in the design of our new system. These philosophies are as follows:
Embrace the Differences of the Devices
Separate Content Gathering from Content Formatting/Delivery
Redefine the Border Between “Client” and “Server”
Distribute Innovation
I will go into more detail below about each of these, including our implementation and what the benefits (and potential detriments) are of this approach. However, each philosophy reflects our top-level goal: to provide whatever is best for the Netflix customer. If we can improve the interaction between the API and our UIs, we have a better chance of making more of our customers happier.
Now, the philosophies…
Embrace the Differences of the Devices
The key driver for this redesigned API is the fact that there are a range of differences across the 800+ device types that we support. Most APIs (including the REST API that Netflix has been using since 2008) treat these devices the same, in a generic way, to make the server-side implementations more efficient. And there is good reason for this approach. Providing an OSFA API allows the API team to maintain a solid contract with a wide range of API consumers because the API team is setting the rules for everyone to follow.
While effective, the problem with the OSFA approach is that its emphasis is to make it convenient for the API provider, not the API consumer. Accordingly, OSFA is ignoring the differences of these devices; the differences that allow us to more optimally take advantage of the rich features offered on each. To give you an idea of these differences, devices may differ on:
Memory capacity or processing power, potentially modifying how much content it can manage at a given time
Requirements for distinct markup formats and broader device proliferation increases the likelihood of this
Document models, some devices may perform better with flatter models, others with more hierarchical
Screen real estate which may impact the content elements that are needed
Document delivery, some performing better with bits streamed across HTTP rather than delivered as a complete document
User interactions, which could influence the metadata fields, delivery method, interaction model, etc.
Our new model is designed to cut against the OSFA paradigm and embrace the differences across devices while supporting those differences equally. To achieve this, our API development platform allows each UI team to create customized endpoints. So the request/response model can be optimized for each team’s UIs to account for unique or divergent device requirements. To support the variability in our request/response model, we need a different kind of architecture, which takes us to the next philosophy…
Separate Content Gathering from Content Formatting/Delivery
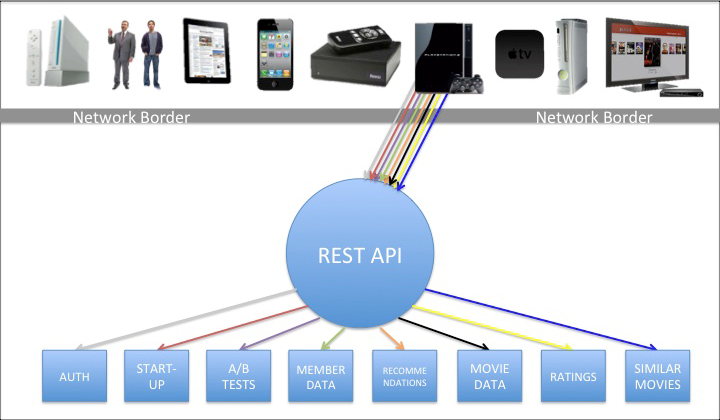
In many OSFA implementations, the API is the engine that retrieves the content from the source(s), prepares that payload, and then ultimately delivers it. Historically, this implementation is also how the Netflix REST API has operated, which is loosely represented by the following image:
The above diagram shows a rainbow of colors roughly representing some of the different requests needed for the PS3, as an example, to start the Netflix experience. Other UIs will have a similar set of interactions against the OSFA REST API given that they are all required by the API to adhere to roughly the same set of rules. Inside the REST API is the engine that performs the gathering, preparation and delivery of the content (indifferent to which UI made the request).
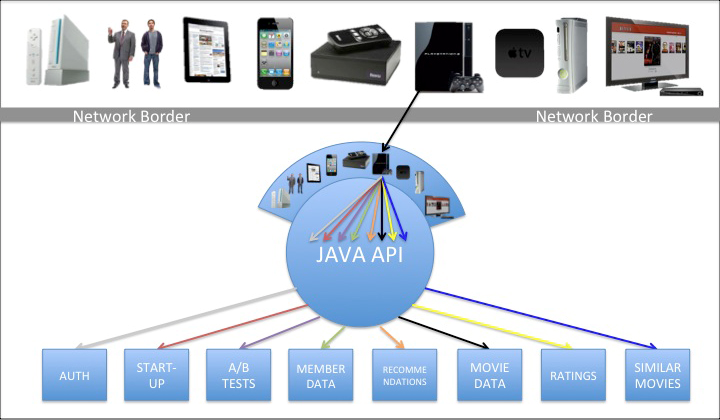
Our new API has departed from the OSFA API model towards one that enables fine-grained customizations without compromising overall system manageability. To achieve this model, our new architecture clearly separates the operations of content gathering from content formatting and delivery. The following diagram represents this modified architecture:
In this new model, the UIs make a single request to a custom endpoint that is designed to specifically handle that request. Behind the endpoint is a handler that parses the request and calls the Java API, which gathers the content by calling back to a range of dependent services. We will discuss in later posts how we do this, particularly in how we parse the requests, trigger calls to dependencies, handle concurrency, support fallbacks, as well as other techniques we use to ensure optimized and accurate gathering of the content. For now, though, I will just say that the content gathering from the Java API is generic and independent of destination, just like the OSFA approach.
After the content has been gathered, however, it is handed off to the formatting and delivery engines which sit on top of the Java API on the server. The diagram represents this layer by showing an array of different devices resting on top of the Java API, each of which corresponds to the custom endpoints for a given UI and/or set of devices. The custom endpoints, as mentioned earlier, support optimized request/response handling for that device, which takes us to the next philosophy…
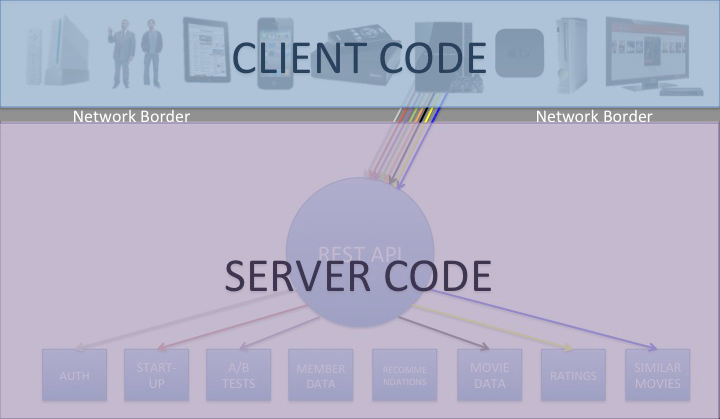
Redefine the Border Between “Client” and “Server”
The traditional definition of “client code” is all code that lives on a given device or UI. “Server code” is typically defined as the code that resides on the server. The divide between the two is the network border. This is often the case for REST APIs and that border is where the contract between the API provider and API consumer is engaged, as was the case for Netflix’s REST API, as shown below:
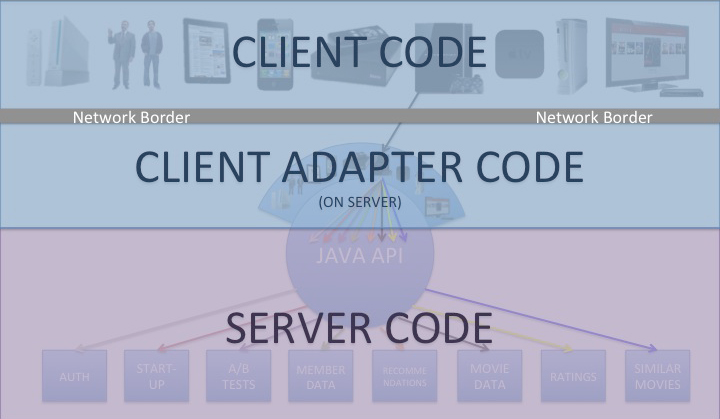
In our new approach, we are pushing this border back to the server, and with it goes a substantial portion of the UI-specific content processing. All of the code on the device is still considered client code, but some client code now resides on the server. In essence, the client code on the device makes a network call back to a dedicated client adapter that resides on the server behind the custom endpoint. Once back on the server, the adapter (currently written in Groovy) explodes that request out to a series of server-side calls that get the corresponding content (in some cases, roughly the same rainbow of requests that would be handled across HTTP in our old REST API). At that point, the Java APIs perform their content gathering functions and deliver the requested content back to the adapter. Once the adapter has some or all of its content, the adapter processes it for delivery, which includes pruning out unwanted fields, error handling and retries, formatting the response, and delivering the document header and body. All of this processing is custom to the specific UI. This new definition of client/server is represented in the following diagram:
There are two major aspects to this change. First, it allows for more efficient interactions between the device and the server since most calls that otherwise would be going across the network can be handled on the server. Of course, network calls are the most expensive part of the transaction, so reducing the number of network requests improves performance, in some cases by several seconds. The second key component leads us to the final (and perhaps most important) philosophy to this approach, which is the distribution of the work for building out the optimized adapters.
Distribute Innovation
One expected critique with this approach is that as we add more devices and build more UIs for A/B and multivariate tests, there will undoubtedly be myriad adapters needed to support all of these distinct request profiles. How can we innovate rapidly and support such a diverse (and growing) set of interactions? It is critical for us to support the custom adapters, but it is equally important for us to maintain a high rate of innovation across these UIs and devices.
As described above, pushing some of the client code back to the servers and providing custom endpoints gives us the opportunity to distribute the API development to the UI teams. We are able to do this because the consumers of this private API are the Netflix UI and device teams. Given that the UI teams can create and modify their own adapter code (potentially without any intervention or involvement from the API team), they can be much more nimble in their development. In other words, as long as the content is available in the Java API, the UI teams can change the code that lives on the device to support the user experience and at the same time change the adapter code to deliver the payload needed for that experience. They are no longer bound by server teams dictating the rules and/or being a bottleneck for their development. API innovation is now in the hands of the UI teams! Moreover, because these adapters are isolated from each other, this approach also diminishes the risk of harming other device implementations with tactical changes in their device-specific APIs.
Of course, one drawback to this is that UI teams are often more skilled in technologies like HTML5, CSS3, JavaScript, etc. In this system, they now need to learn server-side technologies and techniques. So far, however, this has been a relatively small issue, especially since our engineering culture is to hire very strong, senior-level engineers who are adaptable, curious and passionate about learning and implementing these kinds of solutions. Another concern is that because the UI teams are implementing server-side adapters, they have the potential to bring down the servers through infinite loops or other processes that are resource intensive. To offset this, we are working on scrubbing engines that will hopefully minimize the likelihood of such mistakes. That said, in the OSFA world, code on the device can just as easily DDOS the server, it is just potentially a bigger problem if it runs on the server.
Example of how this new system works:
A device, such as the PS3, makes a single request across the network to load the home screen (This code is written and supported by the PS3 UI team.
A Groovy adapter receives and parses the PS3 request (PS3 UI team)
The adapter explodes that one request into many requests that call the Java API to (PS3 UI team)
Each Java API calls back to a dependent service, concurrently when appropriate, to gather the content needed for that sub-request (API team)
In the Java API, if a dependent service unavailable or returns a 4xx or 5xx, the Java API returns a fallback and/or an error code to the adapter (API team)
Successful Java API transactions then return the content back to the adapter when each thread has completed (API team)
The adapter can handle the responses from each thread progressively or all together, depending on how the UI team wants to handle it (PS3 UI team)
The adapter then manipulates the content, retrieves the wanted (and prunes out the unwanted) elements, handle errors, etc. (PS3 UI team)
The adapter formats the response in preparation for delivery back across the network to the PS3, which includes everything needed for the PS3 home screen in the single payload (PS3 UI team)
The adapter finally handles the delivery of the payload across the network (PS3 UI team)
The device will then parse this optimized response and populate the UI (PS3 UI team)
We are still in the early stages of this new system. Some of our devices have fully migrated over to it, others are split between it and the REST API, and others are just getting their feet wet. In upcoming posts, we will share more about the deeper technical aspects of the system, including the way we handle concurrency, how we manage the adapters, the interaction between the adapters and the Java API, our Groovy implementation, error handling, etc. We will also continue to share the evolution of this system as we learn more about it.
The first place I had ever seen an API actually at work was as part of an operating system. It was a strange OS at that, a permutation of CP/M that used a graphical front end called GEM, which would later be ported to the Atari ST. The definition was explained to me like this: An “interface,” as everyone knows, is a specification for how electrical components interconnect. Well, now it’s possible for an application program – the part that does what users need – to interconnect with the operating system, which does what the computer needs. This way the operating functions don’t have to be built into every program, they can just be handed off to the OS and the connection will look seamless. The principle was called a layer of abstraction. It was 1984, and it was the first time I’d heard the term.
It would be wrong to call the concept “revolutionary,” unless you measure time in units of eons. Nearly three decades after its introduction, only recently have businesses come to realize how widely this architectural principle could be applied. No longer do complex processes have to be bound to precise, policy-intrinsic procedures. If teams can work independently, and computer resources devised to suit each team individually, then all that needs to be specified is the exchange of information between them.
So it is that a software designer ends up becoming one of the public faces of the ideal of API architecture as a business tool. Daniel Jacobson is the lead API engineer for Netflix – arguably the largest single consumer of bandwidth on the entire Internet. His O’Reilly book, APIs: A Strategy Guide, co-authored with Apigee CTO Greg Brail and research editor Dan Wood, deals with the implementation of APIs not so much for software’s own exclusive purposes, but moreover as a means of realigning and renovating business’ resources overall.
“APIs should not be geeky ‘science projects,’” reads the first paragraph of Chapter 4. “They are critical business tools. Successful APIs need clear objectives that relate directly to business objectives and track closely to key performance indicators for the business at large.”
More open on the inside
We’ve written here in ReadWriteWeb in the past about the value of APIs in providing transparency and accessibility to businesses, mainly through enabling them to develop mobile apps that connect more directly to their customers. Jacobson has a different perspective, which derives from his experience with Netflix, and earlier as the creator of the API for NPR. It was in 2002 that Jacobson and his NPR team made discoveries that he describes as part logic, part luck.
“At that time, a lot of publishers would be buying these CMSes, off-the-shelf products like Interwoven or Vignette,” Jacobson relates to RWW. “And the flexibility, and the opportunity for thinking in these [new] kinds of ways, was somewhat limited.”
Subsisting sometimes from month to month on public and government funding, NPR didn’t have the budget to go big and invest in a colossal, support-intensive CMS like Vignette – an investment which, at that time, often cost bigger businesses tens if not hundreds of thousands per year, after including maintenance costs. Faced with no other obvious option, NPR was forced to go it alone, building its own CMS. And in recognizing the need to maximize its efficiency, Jacobson and his colleagues decided that their system had to be designed from the beginning to be flexible enough to publish to any platform, including those that had not yet been created.
So NPR adopted a design philosophy called COPE: Create Once, Publish Everywhere.
“That was the really fortunate decision that we made… We didn’t think about iPhones and tablets, and things like that, in 2002. But we were thinking that we could imagine a case somewhere down the road where the Web site would need to change again, or we’re going to do another redesign… It was really important for us to have this COPE model, so we can actually capture all the metadata that’s important to us in a very modularized way so that, regardless of what the display is going to look like, we can publish to it very easily. So conceptually, we separated the idea of capturing the data from presenting the data.”
It was NPR’s first abstraction layer. But it was not yet an API, mainly because the CMS and the database were still tightly bound. To this day, businesses that invested in content management systems around the year 2000 are wrestling with the headaches of data portability, because their CMS is too tightly bound to its database, and the database has become a rusty, misbehaving vault.
The interface as publishing
It was 2007. While NPR had a system that could publish anywhere, the create-once part was giving it problems. The creation was becoming a frightful mess.
“It was that moment in 2007, I think, when we said, we’ll need another abstraction layer to separate out the direct access from the presentation layer to the database, even though we had conceptualized them as being different, that binding to the database was still there. That’s when we created this new abstraction layer of the API, and shortly after that, [we realized] we could open this thing up quickly.”
The process of integrating the abstraction layer was entirely internal, and its goals were focused on how NPR could retool itself. But in making that change, the organization realized it could effectively publish the benefits of that abstraction in a way that was entirely in keeping with the goals of its COPE methodology. Dan Jacobson tells us that, in this phase of the project, he incorporated another important ethic, this time straight from the world of broadcasting: Know your audience. More specifically, build each component of the system in tune with the needs of its consumer.
Jacobson’s book suggests that more businesses either nurture or hire someone who can serve as the technologist for their company, and make it this person’s job to know the audience – to understand how data is being consumed and who is doing the consuming. “And then understand what abstraction layer, like an API, needs to be put in place,” he explains, “to basically be the glue between the capturing of the data and the presentation to its users.”
One term Jacobson often borrows from the software development world and applies to the business world is context. He uses it to mean the breadth of a person’s influence in the company, and there are reasons that influence may be limited. But only through understanding the different contexts of business units, he feels, can a developer build an API that enables them to interoperate.
“Publishers are thinking about how can they create an organization that will put them in a position for this kind of rapid growth,” Dan Jacobson continues. “At Netflix now, we have several hundred devices running off our API. Many publishers of various kinds would love to have that kind of distribution. You need your technologists in a position to have the context and the trust of the superiors, and basically everybody on board with making smart decisions and allowing them to execute. The larger the company sometimes, the more bureaucracy there is, and the more they need to have these discussions. They’re basically, potentially, shackling their people… Here, you’re putting them in a position to make decisions for you.”
Fate has an interesting way of making itself appear coincidental. Had NPR not been so constrained by its own budget limitations, it might never have hired the team that designed their CMS and that implemented COPE in the first place. And it might still be bound by the same tight, complex information architecture that binds so many bigger commercial enterprises to this day.
“I think it’s the confluence of a range of things – the financial restrictions, having good people, good context, good control of the situation, and making smart decisions – and a little bit of luck,” says Jacobson. “We could have made some smart decisions at the time that weren’t quite as lucky down the road. We were very fortunate.”
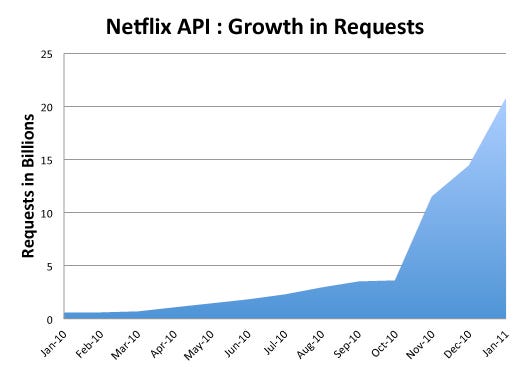
This is Daniel Jacobson, Director of Engineering for the API here at Netflix. The Netflix API launched in 2008 with a focus on the public developer community. The expectation was that this community would build amazing and inspiring applications that would take Netflix to a new level in serving our members. While some fantastic things were built by this community, including sites like Instant Watcher, the transformational moment for the API was when we started to use it to deliver the streaming functionality to Netflix ready devices. In the last year, we have escalated this approach to deliver Netflix metadata through the API to hundreds of devices. All of this has culminated in tremendous growth of the API, as represented by the following chart:
The tremendous growth of the API over the last year is due to a combination of the increased number of users, more activity by our users, Netflix’s steady adoption of new devices over time, as well as chattier interfaces to the API.
Growing the API by about 37× in 13 months indicates a few things to us. First, it demonstrates the tremendous success of the API and the fact that it has become a critical system within Netflix. Moreover, it suggests that, because it is so critical, we have to get it right. When reviewing the founding assumptions of the API from 2008, it is now clear to us that the API needs to be redesigned to carry us into the future.
Establishing New Goals
In the two-and-a-half years that the API has been live, some major, fundamental changes have taken place, both with the API and with Netflix. I already mentioned the change in focus from an exclusively public API to one that also drives our device experiences. Additionally, at the time of the launch, Netflix was primarily focused on delivering DVDs. Today, while DVDs are still part of our identity, the growth of our business is streaming. Moreover, we are no longer US-only. In October, we launched in Canada with a pure streaming plan and we are exploring other international markets as well. Because of these fundamental changes, as well as others that have cropped up along the way, the goals of the API have changed. And because the goals have changed, the way the API needs to operate has as well.
Decreasing Total Requests
An example of where the current design is inefficient is in the way the API resources are modeled. Today, there are about 20 resources in the API. Some of these resources are very similar to each other, although they each have their own interfaces and responses. Because of the number of resources and the fact that we are adhering very closely to the REST conventions, our devices need to make a series of calls to the APIs to get all the content needed to render the user interface. The result is that there is a high degree of chattiness between the devices and the APIs. In fact, one of our device implementations accounts for about 50% of the total API calls. That same device, however, is responsible for significantly less streaming traffic. Why is this device so chatty? Can we design our API to reduce the number of calls needed to create the same experience? In essence, assuming everything remains static, could the 20+ billion requests that we handled in January 2011 have been 15 billion? Or 10 billion?
Decreasing Payload
If we reduce the number of requests to the API to achieve the same user experience, it implies that the payload of each request will need to be larger. While it is possible that this extra payload won’t noticeably impair performance, we still would like to reduce the total number of bits delivered. To do so, we will also be looking at ways to handle partial response through the API. Our goal in this approach will be to conceptualize the API as a database. A database can handle incredible variability in requests through SQL. We want the API to be able to answer questions with the same degree of variability that SQL can for a database. Other implementations, like YQL and OData, offer similar flexibility and we will research them as well. Chattiness and payload size (as well as their impact on the request/response model) are just two examples of the things we are researching in our upcoming API redesign. In the coming weeks, as we get deeper into this work, we will continue to post our thinking to this blog.
If these challenges seem exciting to you, we are hiring! Check out the jobs on the API team at our jobs site.
Last night, I had the pleasure of joining my old colleagues from NPR at the Online Journalism Association’s award ceremony in DC. First of all, it was great to see the gang again after three weeks as a non-NPR employee. It was also great to see NPR nominated for a wide range of awards (eight in total). The highlights for me, however, were that the NPR API won its first award (explicitly) and the fact that Kinsey Wilson won the Rich Jaroslovsky award (congratulations, Kinsey!).
The NPR API won the Gannett Foundation Award for Technical Innovation in the Service of Digital Journalism, which is a huge honor! I couldn’t be more proud of the NPR team, and more specifically the NPR Digital Media Tech Team, in claiming this. The work that the team did is amazing and it is great to see that work getting recognized in such a prestigious fashion. I am also very thankful that Kinsey invited me to accept the award on behalf of NPR. Representing such a tremendous team in this forum is a huge honor for me. While accepting the award, I explicitly thanked Zach Brand and Harold Neal as my “partners in crime” in getting the API live. While I stand by that statement, I do wish I explicitly thanked the rest of the Tech Team who has played a very important role in the evolution of the API since its launch in 2008.
Congratulations to Demian Perry, Jeremy Pennycook, Jennifer Oh and the other contributors to NPR Mobile as well, for winning the award for Outstanding Use of Emerging Technologies.
I look forward to seeing more great achievements from NPR going forward. I expect that there will be many…