ProgrammableWeb : 7 Ways to Make Your API More Successful
I originally published this article to ProgrammableWeb.com on December 10, 2012
The purpose of a content API is to make the content available to its audience in the most useful and efficient way possible. To be a useful API, it needs to help the developers make their jobs easier. This could mean a wide range of things, including making it easier to dig into the API, allowing for greater flexibility in the responses, improved performance and efficiency for both the API and its consumer. Below are seven development techniques (all of which are part of the NPR API) that can help content providers improve the usefulness and efficiency of their APIs on both sides of the track. These techniques played a critical role in the success of the API which now delivers over 700 million stories per month to its users (more stats on the NPR API coming soon on our Inside NPR.org blog).
Be Flexible: Support Multiple Output Formats
Making the API as available and accessible as possible is very important in drawing developers to use it. So providing the content in a range of formats will increase the likelihood that the developer can rely on existing libraries and make as few changes to the code as possible.
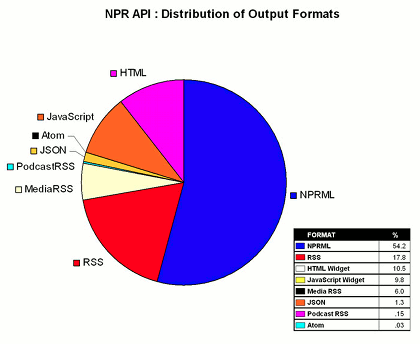
The NPR API offers eight different output formats in an effort to improve efficiency for the developers. Above is a graph demonstrating the distribution of requests for each of the formats in July of 2009. As you can see, the majority of requests are to our proprietary XML markup (NPRML). That also means that almost 50% of the requests, or about 20M requests per month, use the other seven formats. In offering offering these other non-proprietary XML formats, the API is able to support developers that may have existing applications that pull in content in one of these standardized format, such as MediaRSS or Atom.
To make it even easier for people to use the API, NPR also launched with JavaScript and HTML “widgets”. The other six formats require more sophistication in order to put the content in an application or website. The widgets, however, are pre-designed feeds of NPR content (based on the developer’s selections) that can be easily dropped into a page.
Be Efficient: Handle Partial Response
This concept is now starting to get some more traction, now that Google announced partial response handling for some of their APIs. NPR’s API also makes extensive us of this feature because it really is tremendously valuable to the provider and the consumer of the API. For example, NPR stories contain a wide variety of fields and assets in the API. If the consumer is forced to handle the complete document, even if they only want a few fields, they have to endure all of the latency issues from the API itself as well as the additional processing power needed to handle the undesired fields.
As a result, NPR incorporated a “fields” parameter (the same parameter name used by Google) that can be used in the query string to limit the resulting document to only the fields of interest. This approach creates documents that are smaller and much more efficient. Overwhelmingly, more requests to the NPR API contain the fields parameter than those that do not (in fact, it isn’t even close).
Here are a few examples of how the same query to the NPR API, returning the same stories, delivers different documents based on the fields parameter (you will need to register for your own NPR API key to execute these queries):
http://api.npr.org/query?id=1001&apiKey=your_api_key
http://api.npr.org/query?id=1001&fields=title&apiKey=your_api_key
http://api.npr.org/query?id=1001&fields=title,teaser,text,image,audio&apiKey=your_api_key
An extension of partial response is to allow the developer to specify the number of items they would like in return. Some APIs return a fixed number of results, which can bloat the document just like the extra fields can. The NPR API, to counter this, allows the developer to pass in the number of results desired (with a fixed ceiling for any given request). To dig deeper in the results, we incorporated a “pagination” feature in the API. Here are some examples of how to control the number of stories:
http://api.npr.org/query?id=1001&numResults=5&apiKey=your_api_key
http://api.npr.org/query?id=1001&numResults=5&startNum=6&apiKey=your_api_key
Give Them Control: Allow for Customizable Output Markup (“Remapping Fields”)
As mentioned in the transform section, if the API can easily serve existing applications that expect specific markup, it potentially increases adoption and improves developer efficiency. To extend that functionality, the NPR API offers a function that we call “Remap” which essentially lets the developer modify the name of one or more XML elements or attributes in the output at request time. This is done in the query string and the API transforms the markup accordingly in real-time. Here are a few examples:
In this example, the remap parameter changes the story title to < specialTitle >:
http://api.npr.org/query?id=1001&remap=list.story.title:specialTitle&apiKey=your_api_key
In this example, the remap parameter changes the story title to < specialTitle > and it changes the image caption to < imageCaption >:
http://api.npr.org/query?id=1001&remap=list.story.title:specialTitle,list.story.image.caption:imageCaption&apiKey=your_api_key
In this example, the remap parameter changes the audio element’s id attribute to be named audioId:
http://api.npr.org/query?id=1001&remap=list.story.audio~id:audioId&apiKey=your_api_key
Another benefit to remap (which we have fortunately not had to use) is that it can be used to handle backward compatibility as the API grows and changes. NPR’s philosophy is to make sure that upgrades do not adversely affect existing functionality. That said, if an element or attribute does need to change, we could execute apache rewrites for all old API calls and have the remap function applied to have the output match that of the old markup. Alternatively, the developer could simply modify their API call instead of having to change their codebase to match the markup changes. (Although we do not intend to change existing markup, if we do, we would advise developers to upgrade their code accordingly. That said, rather than having the applications fail during the transition, remap could be used to temporarily handle requests until the full codebase can be upgraded).
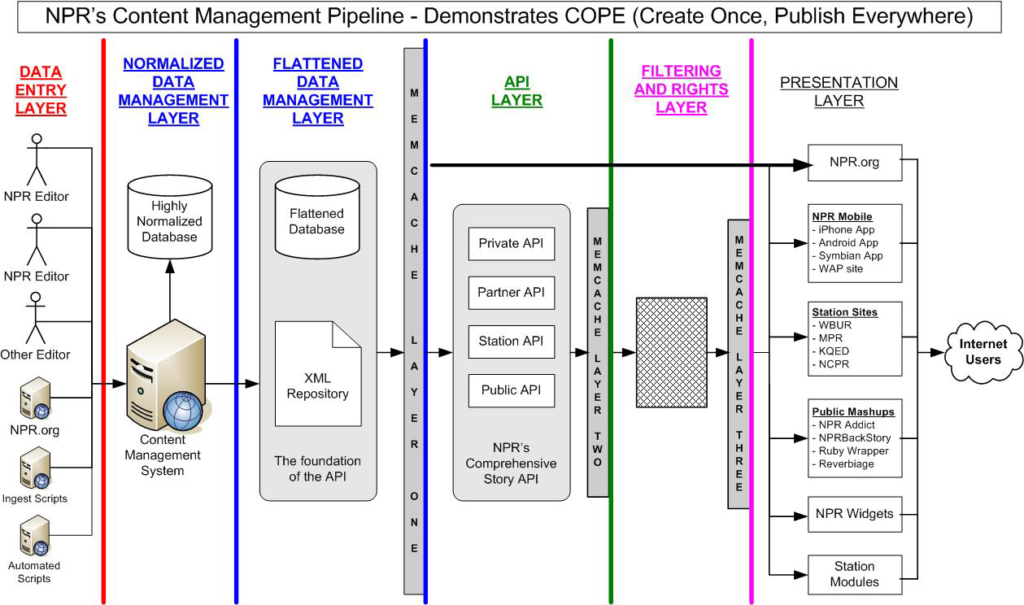
Be Fast: Set Up a Comprehensive Caching Architecture
Performance is another critical aspect of APIs when it comes to enticing developers to use them. After all, if the API is sluggish, developers may not want to depend their application on it.
Smart caching of queries and results can really improve the speed of the system. NPR has implemented several layers of caching for the API, as follows:
- Base XML – Caching the full document for each item is important to prevent the system from executing disk I/O before doing any transform. We cache the Base XML first in memory and secondarily as XML files to eliminate the need to access our content database.
- Full Query Results – When compiling the list of items to be returned for any given story, it is important to cache the full list because popular applications that have many concurrent users (such as NPR Addict) are very likely to execute the same queries and expect the same results. The cached result is a single document containing the full list of all items and the full base XML for each.
- Transformed Query Results – The calling application, such as NPR Addict, expects the document to be transformed to fit the application’s needs. So, the results that get cached in Full Query Results may get transformed to MediaRSS while simultaneously removing extraneous fields. Caching the final results that get returned to the calling application enable fastest performance without compromising the system’s ability to use the other caching layers to produce different versions of the document.
Give Them Tools: Provide a Query UI with the Documentation
There are two truths about developers and documentation: the former always expects the latter, but seldom uses it. Of course, you cannot have an API without providing comprehensive documentation. That said, offering a simple user interface that helps developers get what they need from the API wil increase adoption and make life easier for them.
NPR’s API launched with a tool that we call the Query Generator. This tool exposes more than 6500 query-able IDs, methods for controlling the output format, fields to be returned, date and search restrictions, pagination, and more. Using the interface, the developer can select their options and have the tool create the query string for their API request. The developer can also see the results of that query inline before commiting it to their application. Almost exclusively, developers (including the NPR staff) use this tool to create queries, rather than reading the documentation.
Be Open: Eliminate Rate Limiting
Throttling or limiting access to APIs is an inherent disincentive for developers. Moreover, it is actually a detriment to the API provider. After all, the purpose of the API is to grant access to the content. If a given developer can only call the API 5000 times a day, and that developer creates a hugely popular application, the rate-limiting will inherently stifle the developer and the viral nature of the API.
Granted, most APIs use rate-limiting or tiered access levels to allow business people to control the graduation of API users. This seems counter-productive to me though. The better approach is to open access completely, identify those incredibly successful usages, then work with the developer accordingly on a mutually beneficial relationship. This way, applications are given full ability to grow and mature without arbitrary constraints.
Other APIs implement rate-limiting to protect the servers from unexpectedly high load. This is a legitimate risk which, if encountered, can adversely affect the performance of all users. That said, building complicated features into the system, such as rate-limiting, can be much more costly than configuring a scalable server architecture. Moreover, each request to the API will see slight latency increases as a result of the rate-limiting analysis. I know that latency is marginal, but why introduce any additional latency, especially when creating disincentives for developers?
Be Agile: Practice Iterative Development
Building your API over time has several benefits. First, it signals to the developer community that this API is meaningful to the provider and will continue to grow and get supported over time. This sounds trivial, but it is a very important part of the relationship with the community. If developers are not sure about your commitment to the API, are they likely to spend their own time building an application around it?
Another benefit of iterative development is that you do not have to get the API perfect the first time. I will qualify that by saying that, as a matter of principle, any release for an API should be done with the expectation that it will be supported for a long time. This is important because changes to existing API features will break the applications of those that use them. When I say the API doesn’t have to be perfect, I mean it does not have to be complete. New features can (and should) be added over time, extending its capability and making it more attractive for potential developers.
To put it another way, you will not have every detail of the API solved at the initial launch. It is much better to go live with the features that you know well while deferring those that you do not. Trying to cram in tenuous requirements will create headaches for you and for the community down the road. Spend the time necessary on figuring out the features, the supporting markup, the access and error methods, etc. before you commit to an API feature.





