On February 8, 2013, I spoke at the Intelligent Content Conference 2013. When Scott Abel (aka The Content Wrangler) first contacted me to speak at the event, he asked me to speak about my content management and distribution experiences from both NPR and Netflix. The two experiences seemed to him to be an interesting blend for the conference. These are the slides from that presentation.
I have applied comments to every slide in this presentation to include the context that I otherwise provided verbally during the talk.
With respect to Web APIs, the industry has clearly and emphatically landed on REST as the standard way to implement these services. And for good reason… REST, which is generally implemented as a one-size-fits-all solution, is an excellent choice for a most companies who wish to expose their content to third parties, mobile app developers, partners, internal teams, etc. There are many tomes about what REST is and how best to implement it, so I won’t go into detail here. But if I were to sum up the value proposition to these companies of the traditional REST solution, I would describe it as:
REST APIs are excellent at handling requests in a generic way, establishing a set of rules that allow a large number of known and unknown developers to easily consume the services that the API offers.
In this model, everyone knows how to behave and it can be incredibly powerful. The API providers establish a set of rules and the API consumers must adhere to those rules to get what they want from the API. It is perfect, right? In many cases, the answer is obviously yes. But in other cases, as our world scales and the number of ways for people to consume digital content and services continues to expand, this one-size-fits-all model is likely to fall short.
The potential shortcomings surface because this model assumes that a key goal of these APIs is to serve a large number of known and unknown developers. The more I talk to people about APIs, however, the clearer it is that public APIs are waning in popularity and business opportunity and that the internal use case is the wave of the future. There are books, articles and case studiescropping up almost daily supporting this view. And while my company, Netflix, may be an outlier because of the scale in which we operate, I believe that we are an interesting model of how things are evolving.
Netflix is currently available on over 800 different device types, including game consoles, mobile phones, TVs, Blu-ray players, tablets, computers, and almost any other device that can stream video. Our API alone handles more than two billion incoming requests on peak days, which translates into almost ten billion real-time outgoing requests from the API to internal dependency services. These numbers are up by about 70x from just two years ago. Most companies do not have that kind of scale, but it is clear that with the continued growth of the device market more companies are resetting their strategies to be less about the public API and more about internal consumption of their own APIs to support device proliferation. When this transition occurs, the API is no longer targeting “a large number of known and unknown developers.” Rather, the key audience is a small number of known developers.
The potential conflict between the internal and public use cases is in the design of the API itself. Keep in mind that the design implications will not be problematic in many scenarios. It becomes a potential problem if the breadth of devices becomes so wide that the variability of features across them becomes substantially harder to manage. It is the breadth of devices that creates a problem for the one-size-fits-all API solutions.
If your target is a small group of teams with whom you have close relationships, the dynamics around the API change. For Netflix, we persisted on the one-size-fits-all REST model for quite a while as more and more devices got added on top of the API. But given our scale, one thing has become increasingly obvious. Our REST API, while very capable of handling the requests from our devices in a generic way, is optimized for none of them. This is the case because our REST API focuses on resources that are meant to be granular representations of the data, from the perspective of the data. The granularity is exactly what allows the API to support a large number of known and unknown developers. Because it sets the rules for how to interface with the data, it also forces all of the developers to adhere to those rules. That means that each device potentially has to work a little harder (or sometimes a lot harder) to get the data needed to create great user experiences because devices are different from each other.
The differences across these devices can be varied and sometimes significant. Here are some examples of variances across devices that may be challenging for one-size-fits-all models:
Different devices may have different memory capacity
Some devices may require a unique or proprietary format or delivery method
Some devices may perform better with a flatter or more hierarchical document model
Different devices have different screen real estate sizes which may impact which data elements are needed
Some devices may perform better having bits streamed across HTTP rather than delivered as a complete document
Different devices allow for different user interaction models, which could influence the metadata fields, delivery method, interaction model, etc.
Just think about the differences between an iPhone and your TV and how they beg for different user experiences. Moreover, the XBox and the Wii, both of which project to the TV, are different in the way users interact with them as well as in the hardware constraints, both of which may require different APIs to support them. When considering more than 800 different device types, the variance across them becomes overwhelming. And as more manufacturers continue to innovate on these devices, the variance may only broaden.
How do you know if your company is ready to consider alternatives to the one-size-fits-all API model? Here are the ingredients needed to help you make that decision:
Small number of targeted API consumers is the top priority
Very close relationships between these API consumers and the API team
An increasing divergence of needs across the top priority API consumers
Strong desire by the API consumers for more optimized interactions with the API
High value proposition for the company providing the API to make these API consumers as effective as possible
If these ingredients are met, then you have the recipe for needing a new kind of API.
Because of the differences in these devices, Netflix UI teams would often have to do a range of things to get around our REST API to better serve the users of the device. Sometimes, the API team would be required to extend the base service to handle special cases, often resulting in spaghetti code or undocumented features. And because different teams have different needs, in the REST API world, we would often need to delay feature development for some due to the challenges around prioritization. In addition to these kinds of issues, significant performance and/or architectural problems are bound to emerge. For example, these more granular APIs often result in chattier interactions between device and server or chunkier payloads, as I discussed in a previous post on the Netflix Tech Blog.
To solve this issue, it is becoming increasingly common for companies (including Netflix) to think about the interaction model in a different way. Rather than having the API create a set of rather rigid rules and forcing the various devices to follow them, companies are now thinking about ways to let the UI have more control in dictating what is needed from a service in support of their needs. Some are creating custom REST-based APIs to support a specific device or category of devices. Others are thinking about greater granularity in REST resources with more batching of calls. Some are creating orchestration layers, such as ql.io, in their API system to customize the interaction. These are all smart and practical ways around the problem. But with the growing number of devices, the increasing urge for companies to be on as many of them as possible, and the desire for continued innovation across these devices, these various solutions are still somewhat restricted. They are still forcing the developers to adhere to server-side rules and non-optimized payloads in an effort to have a one-size-fits-all solution. These approaches are closer to the flexibility needed in that they are not as rigid as the typical REST-based solution, but when supporting as many devices as Netflix does, we believe they fall short for us.
For Netflix, our goal is to take advantage of the differences of these devices rather than treating them generically. As a result, we are handing over the creation of the rules to the developers who consume the API rather than forcing them to adhere to a generic set of rules applied by the API team. In other words, we have created a platform for API development.
I originally published this article to ProgrammableWeb.com on December 10, 2012
The purpose of a content API is to make the content available to its audience in the most useful and efficient way possible. To be a useful API, it needs to help the developers make their jobs easier. This could mean a wide range of things, including making it easier to dig into the API, allowing for greater flexibility in the responses, improved performance and efficiency for both the API and its consumer. Below are seven development techniques (all of which are part of the NPR API) that can help content providers improve the usefulness and efficiency of their APIs on both sides of the track. These techniques played a critical role in the success of the API which now delivers over 700 million stories per month to its users (more stats on the NPR API coming soon on our Inside NPR.org blog).
Be Flexible: Support Multiple Output Formats
Making the API as available and accessible as possible is very important in drawing developers to use it. So providing the content in a range of formats will increase the likelihood that the developer can rely on existing libraries and make as few changes to the code as possible.
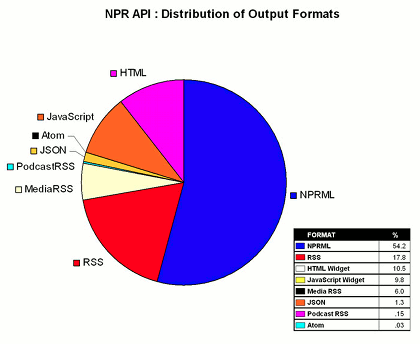
The NPR API offers eight different output formats in an effort to improve efficiency for the developers. Above is a graph demonstrating the distribution of requests for each of the formats in July of 2009. As you can see, the majority of requests are to our proprietary XML markup (NPRML). That also means that almost 50% of the requests, or about 20M requests per month, use the other seven formats. In offering offering these other non-proprietary XML formats, the API is able to support developers that may have existing applications that pull in content in one of these standardized format, such as MediaRSS or Atom.
To make it even easier for people to use the API, NPR also launched with JavaScript and HTML “widgets”. The other six formats require more sophistication in order to put the content in an application or website. The widgets, however, are pre-designed feeds of NPR content (based on the developer’s selections) that can be easily dropped into a page.
Be Efficient: Handle Partial Response
This concept is now starting to get some more traction, now that Google announced partial response handling for some of their APIs. NPR’s API also makes extensive us of this feature because it really is tremendously valuable to the provider and the consumer of the API. For example, NPR stories contain a wide variety of fields and assets in the API. If the consumer is forced to handle the complete document, even if they only want a few fields, they have to endure all of the latency issues from the API itself as well as the additional processing power needed to handle the undesired fields.
As a result, NPR incorporated a “fields” parameter (the same parameter name used by Google) that can be used in the query string to limit the resulting document to only the fields of interest. This approach creates documents that are smaller and much more efficient. Overwhelmingly, more requests to the NPR API contain the fields parameter than those that do not (in fact, it isn’t even close).
Here are a few examples of how the same query to the NPR API, returning the same stories, delivers different documents based on the fields parameter (you will need to register for your own NPR API key to execute these queries):
An extension of partial response is to allow the developer to specify the number of items they would like in return. Some APIs return a fixed number of results, which can bloat the document just like the extra fields can. The NPR API, to counter this, allows the developer to pass in the number of results desired (with a fixed ceiling for any given request). To dig deeper in the results, we incorporated a “pagination” feature in the API. Here are some examples of how to control the number of stories:
Give Them Control: Allow for Customizable Output Markup (“Remapping Fields”)
As mentioned in the transform section, if the API can easily serve existing applications that expect specific markup, it potentially increases adoption and improves developer efficiency. To extend that functionality, the NPR API offers a function that we call “Remap” which essentially lets the developer modify the name of one or more XML elements or attributes in the output at request time. This is done in the query string and the API transforms the markup accordingly in real-time. Here are a few examples:
In this example, the remap parameter changes the story title to < specialTitle >:
Another benefit to remap (which we have fortunately not had to use) is that it can be used to handle backward compatibility as the API grows and changes. NPR’s philosophy is to make sure that upgrades do not adversely affect existing functionality. That said, if an element or attribute does need to change, we could execute apache rewrites for all old API calls and have the remap function applied to have the output match that of the old markup. Alternatively, the developer could simply modify their API call instead of having to change their codebase to match the markup changes. (Although we do not intend to change existing markup, if we do, we would advise developers to upgrade their code accordingly. That said, rather than having the applications fail during the transition, remap could be used to temporarily handle requests until the full codebase can be upgraded).
Be Fast: Set Up a Comprehensive Caching Architecture
Performance is another critical aspect of APIs when it comes to enticing developers to use them. After all, if the API is sluggish, developers may not want to depend their application on it.
Smart caching of queries and results can really improve the speed of the system. NPR has implemented several layers of caching for the API, as follows:
Base XML – Caching the full document for each item is important to prevent the system from executing disk I/O before doing any transform. We cache the Base XML first in memory and secondarily as XML files to eliminate the need to access our content database.
Full Query Results – When compiling the list of items to be returned for any given story, it is important to cache the full list because popular applications that have many concurrent users (such as NPR Addict) are very likely to execute the same queries and expect the same results. The cached result is a single document containing the full list of all items and the full base XML for each.
Transformed Query Results – The calling application, such as NPR Addict, expects the document to be transformed to fit the application’s needs. So, the results that get cached in Full Query Results may get transformed to MediaRSS while simultaneously removing extraneous fields. Caching the final results that get returned to the calling application enable fastest performance without compromising the system’s ability to use the other caching layers to produce different versions of the document.
Give Them Tools: Provide a Query UI with the Documentation There are two truths about developers and documentation: the former always expects the latter, but seldom uses it. Of course, you cannot have an API without providing comprehensive documentation. That said, offering a simple user interface that helps developers get what they need from the API wil increase adoption and make life easier for them.
NPR’s API launched with a tool that we call the Query Generator. This tool exposes more than 6500 query-able IDs, methods for controlling the output format, fields to be returned, date and search restrictions, pagination, and more. Using the interface, the developer can select their options and have the tool create the query string for their API request. The developer can also see the results of that query inline before commiting it to their application. Almost exclusively, developers (including the NPR staff) use this tool to create queries, rather than reading the documentation.
Be Open: Eliminate Rate Limiting
Throttling or limiting access to APIs is an inherent disincentive for developers. Moreover, it is actually a detriment to the API provider. After all, the purpose of the API is to grant access to the content. If a given developer can only call the API 5000 times a day, and that developer creates a hugely popular application, the rate-limiting will inherently stifle the developer and the viral nature of the API.
Granted, most APIs use rate-limiting or tiered access levels to allow business people to control the graduation of API users. This seems counter-productive to me though. The better approach is to open access completely, identify those incredibly successful usages, then work with the developer accordingly on a mutually beneficial relationship. This way, applications are given full ability to grow and mature without arbitrary constraints.
Other APIs implement rate-limiting to protect the servers from unexpectedly high load. This is a legitimate risk which, if encountered, can adversely affect the performance of all users. That said, building complicated features into the system, such as rate-limiting, can be much more costly than configuring a scalable server architecture. Moreover, each request to the API will see slight latency increases as a result of the rate-limiting analysis. I know that latency is marginal, but why introduce any additional latency, especially when creating disincentives for developers?
Be Agile: Practice Iterative Development
Building your API over time has several benefits. First, it signals to the developer community that this API is meaningful to the provider and will continue to grow and get supported over time. This sounds trivial, but it is a very important part of the relationship with the community. If developers are not sure about your commitment to the API, are they likely to spend their own time building an application around it?
Another benefit of iterative development is that you do not have to get the API perfect the first time. I will qualify that by saying that, as a matter of principle, any release for an API should be done with the expectation that it will be supported for a long time. This is important because changes to existing API features will break the applications of those that use them. When I say the API doesn’t have to be perfect, I mean it does not have to be complete. New features can (and should) be added over time, extending its capability and making it more attractive for potential developers.
To put it another way, you will not have every detail of the API solved at the initial launch. It is much better to go live with the features that you know well while deferring those that you do not. Trying to cram in tenuous requirements will create headaches for you and for the community down the road. Spend the time necessary on figuring out the features, the supporting markup, the access and error methods, etc. before you commit to an API feature.
My previous posts focused on COPE (Create Once, Publish Everywhere) and content modularity, the fundamentals for ensuring that content can be managed and distributed to virtually any platform. But ensuring that your content can be delivered to those other platforms does not mean that it can display appropriately on them.
Content often contains very important semantic markup, used to emphasize the content, relate it to other content, describe it, etc. By markup, I mean HTML, character encodings and microformats, among others. Although this markup is important to the content, it also makes it “dirty”, potentially compromising its ability to live and flourish in the myriad places to which it will get distributed. No matter how modular the content is in the database, if it is sullied by this markup, it is not truly portable. As a result, just building an API is not enough. The API needs to be able to distribute the content to any platform in a way that each platform can handle.
To demonstrate this problem around portability, I often use the pre-iPhone iPod as an example. This device did not parse HTML. Rather, tags would simply be printed as strings. When podcasting took off, some NPR titles had HTML tags in them, including < em > and < strong >. Because iPods were not able to render the HTML, titles would like something like, “This is a < em >great< /em > title!” Similar, another fail scenario that is relevant to NPR is an HD Radio display. These devices are also not able to render markup printing these tags to the screen.
There are two primary ways of handling this problem. The more common way is to store the dirty content in the database and to maintain a series of scripts that handle it on the way out. Although this is potentially effective for specific goals, there are some significant problems with it. For starters, stripping out the markup as it gets distributed means that the markup still lives with the content in the database. As a result, as new platforms arise and as markup standards evolve, the markup in the content will remain static. So, each distribution script that handles the markup will need to be carefully maintained and updated accordingly. Moreover, since each distribution platform could have its own compliance with the various forms of markup, each of these outputs may require their own script to handle the content (that is, the more distribution channels there are, the more scripts there are to maintain). Finally, the majority of systems that allow markup in this way do very little to limit the type of markup that is used. Because of the tremendous variance in how the markup is used in the content, these scripts will need to be increasingly complex, causing the accuracy to be tougher to guarantee.
Rather than handling the cleansing process on the way out, NPR has created a system that cleans the content on the way in. The goal here is to save the content in the database in a modular AND portable way. That means that each discrete object type is stored separately while ensuring that text content in each object is devoid of markup. I call this system “Markup Addressing” and here is how it works:
A range of fields in the system are markup-enabled, allowing Editors and scripts to include HTML and other markup values in the content directly.
For each field that allows markup, very specific values are allowed. Some fields allow more, some less, but all fields are limited to nothing more than the 25 tags and character encodings that the system as a whole allows.
We apply client-side handling to ensure that no markup beyond those allowed by the field are used for that field. We also enforce proper nesting and syntax for the markup.
Before saving the clean and acceptable markup to the database, we identify all markup for each field and begin our “addressing”, which is essentially identifying the character numbers of the markup in the text. For each tag or character identified, we find the character position for where it starts. If applicable, we also find the character position for the close tag. We then strip out the markup from the text and store in a relational table the address in the text that the markup was found.
This relational table does not include the markup itself. Rather, that is stored in a separate table that is the authority for which tags are allowable. The image below represents roughly how we store this kind of information.
The diagram above represents how NPR strips out markup from content fields prior to saving to the database. The markup is then “addressed” and stored in a series of relational tables, enabling any presentation layer to present the content with or without markup. It even allows the markup to be easily transformed as needed before pushing to different platforms. (Click here for an enlargement of this diagram)
There are several very tangible benefits to this approach, all of which improve overall portability of the content. These benefits include:
Distributing the content without any markup is as simple as pushing out the content from the database directly, without any further processing. This is helpful for platforms that are unable to render markup, including those mentioned in my examples above.
Distributing the content with the original markup is just as easy by reassembling the markup based on the addresses.
It is easy to only distribute only some of the markup based on what the markup is. An example of this is if the destination product wants to emphasize content but does not want to allow for links to other content.
As markup, such as HTML tags, get deprecated, this approach only requires a change to one field in the entire database, instead of having to cycle through the database to find all instances of the old tag to replace it with the new one. For example, < b > has been replaced with < strong >, so we simply need to modify the one record in the authority table for tags to make this change apply across the entire set of content.
As new platforms arise, if they require specialized markup, it is easy to transform the existing markup to anything else required for these new platforms.
Adding new allowable tags is easy by simply extending the client-side handling and the authority table. These tags can include microformats and other business-critical tags that help describe the content. For example, NPR could very easily create a tag for our internal purposes for < station >, such that for every station that gets tagged, rather than rendering this tag, the system will look up the station in our database and replace that < station > tag with a hyperlink to the station’s home page.
NPR’s system applies these methods to specific fields throughout our CMS. When distributing the content through the API, however, we only currently apply the power of Markup Addressing to the story full text. The API has a field for < text > which removes all markup for the syndication as well as < textWithHtml > which reassembles the content with all markup. Extending this to all other markup-enabled fields would be quite easy under this system, although there has not yet been a need to do so.
Regardless of which approach is taken, there is one other significant issue that prevents true portability of content… the content itself!
I create a distinction between “content” and “calls-to-action” to help clarify this problem. Content is the information that the users actually want to consume. It could also include metadata, which helps to accurately describe the content that the user is actually consuming. Within this content, applying markup that emphasizes it or relates it to other content should be done in such a way that the meaning of the content is unaltered by the abstraction of the markup from the content. Here is an example of an appropriate way to apply markup to the content:
This image is part of an NPR story that demonstrates appropriate use of HTML within the body of the text. The artists’ names are linking to artist pages, but the meaning of the story is completely unaltered by the removal of the markup.
In this scenario, removing the links to the artists’ names in the text, for example, does not alter the meaning of the content. Of course, it does diminish some of its power as the user cannot easily learn more about these artists within the context of this story. That said, distribution of this content without those links will not adversely affect the meaning of the story. The artist names are valid and appropriate within the body of the text.
Applying markup within the content that is calling the users to perform an action, on the other hand, poses a different problem. Here is an example of a call-to-action within the content:
This image is part of the same NPR story demonstrating the use of calls-to-action, which make the content unable to provide meaning without the context of the markup. These calls-to-action make the content less portable, specifically to platforms that are not markup enabled.
Notice that within this content there is a link to related content where the link text is “Listen to The Entire Album”. Abstracting away the link itself actually alters the meaning of the text as the text provides no information about the audio asset. There is no indication as to what album or who the artist is. So, as this content gets distributed to platforms (both known and unknown), pulling out the markup actually adversely affects the content.
This is a problem for every content producer, including NPR. Although we have gone through great measures to put the content in the best position to live and thrive in all platforms, there is still work to be done to ensure the success of our distribution strategies. Some of these efforts are technical in nature. Others could impact editorial processes and style guides. But in all cases, our goals are the same… to be a media organization that produces great content for our users, wherever they wish to consume it.
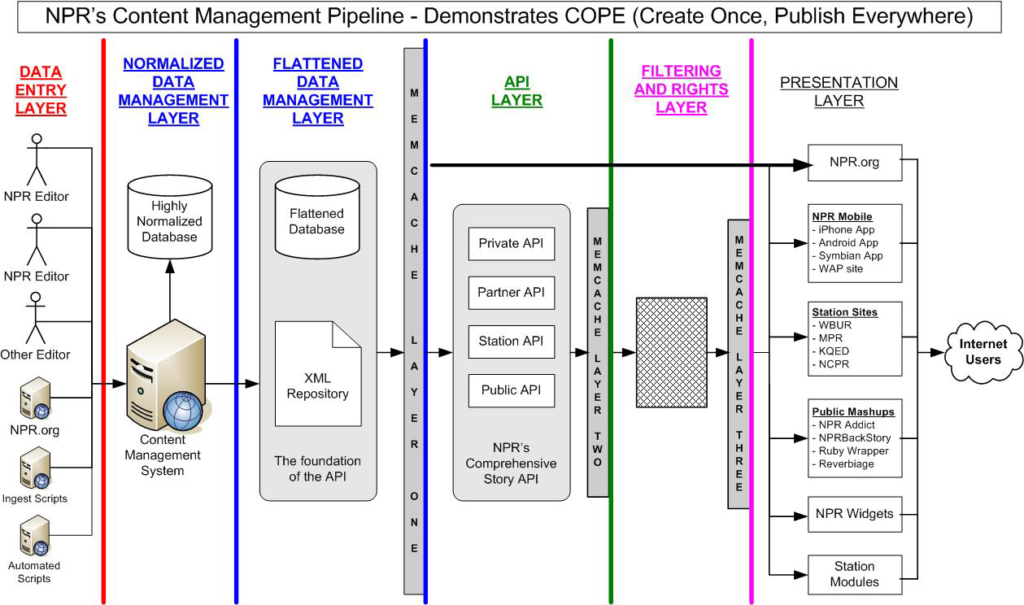
As discussed in my previous post, COPE (Create Once, Publish Everywhere) is a fundamental philosophy that drives NPR’s digital publishing and distribution strategy and is the foundation of the NPR API. Supporting it all is a single system that manages all incoming content and funnels it out through a single distribution pipe, regardless of content type or destination. A key principle that supports COPE is ensuring that content is stored in a modular way.
Modular storage of content is more than just database normalization. It requires strategic design of the data model to ensure that discreet objects are stored in distinct locations. To create the right design, you must truly understand your system and the assets that it stores. That is, you need to be able to identify and represent the object (or series of objects) that is at the core of your system. For NPR, the core of the system is a story. We then attach “resources” to the story, each of which is its own object in the database (examples of resources include full text with each paragraph stored as distinct records, audio, video, images, related links, and a range of other object types). Then stories get attached to lists, which are essentially a series of taxonomies that help our systems slice through the stories.
The diagram above is a basic entity diagram of how NPR manages data for a story, some related resources and the list to which the stories are assigned. This is a conceptual model that represents how these entities relate to each other and does not include all resource or list entities in the system. The physical model, obviously, is much more complex. Click here for a larger and more complete view of this diagram (PDF).
NPR’s system is obviously much more complicated than this, but the breakdown of story/resources/lists is the foundation of it all. Accordingly, storage of this information in the database needs to ensure that all of these objects can be manipulated independently. With this approach, NPR is able to create a list of all images in the system, or all stories that have video, or all stories in the News topic, or any number of other combinations of stories or resources. The power of this modularity is that we have tremendous control over what gets distributed to each destination. And the distribution of content for all of these scenarios is the same simple REST-based API, requiring no special coding to generate the content for the different destinations.
The above is an excerpt of XML outputted from the NPR API. Clean, effective storage of the content makes it a simpler and more flexible process to manage it differently as it gets distributed to different destinations. Click here to see an expanded view of the XML with annotation detailing how it maps to the entity diagram.
Conversely, WPT’s tend to store objects to enable the building of a web page. As a result, the content may be bundled together in database fields, storing the actual references to images, video and audio entirely within the story content text. It is still possible that the WPT’s are adhering to some form of data normalization in their storage techniques, but that does not mean that these systems are embracing COPE.
There are two significant problems with the WPT approach of data storage. First, as an example, the image references within the block of text will contain HTML and possibly other markup, making the text block dirty. Any distribution to other platforms could then require special treatment to prepare the content for that destination. More importantly, however, is the fact that these same images are very difficult to repurpose because they are embedded in text. So, it would be quite a challenge to make a feed of images, to identify only those posts that contain images, to resize some or all images in the system, or to consistently restrict distribution of images that do not have the rights cleared.
Building systems that manage the content in a modular way and separates it from display sets it up well to be distributed on a range of platforms. The final piece to the puzzle, however, is content portability. Content portability ensures that the content can actually live and thrive in all platforms to which it gets distributed (even those that do not yet exist). Building a distribution channel, like an API, is simply not enough anymore. Content portability must be applied at the CMS level, which will be the topic of my next article.