This presentation was original given at OSCON in July, 2011. It was my first OSCON presenting on behalf of Netflix.
The Netflix API was originally launched 3 years ago to expose Netflix metadata and services to developers and build applications. It now handles over 1 billion requests per day from over 20,000 developers and 13,000 applications. However, Netflix has undergone many business changes and the API needs to be redesigned to focus on its core streaming business and support international growth. The new design will build a scalable data distribution pipeline to deliver customized, optimized metadata and services to each streaming client and platform. It will use wrappers and response handlers to customize the response for each device and isolate problems. This will allow faster development and reduce the need for versioning across many client types and interfaces.
I was invited to Bristol, CT in May, 2011 to give this presentation to ESPN’s Digital Media team, focusing on the trajectory of the Netflix API. I also discussed Netflix’s device implementation strategy and how it enables rapid development and robust A/B testing.
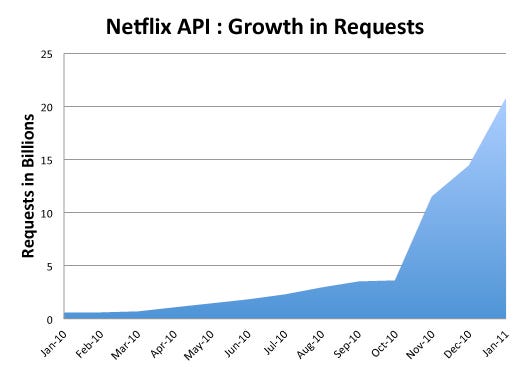
This is Daniel Jacobson, Director of Engineering for the API here at Netflix. The Netflix API launched in 2008 with a focus on the public developer community. The expectation was that this community would build amazing and inspiring applications that would take Netflix to a new level in serving our members. While some fantastic things were built by this community, including sites like Instant Watcher, the transformational moment for the API was when we started to use it to deliver the streaming functionality to Netflix ready devices. In the last year, we have escalated this approach to deliver Netflix metadata through the API to hundreds of devices. All of this has culminated in tremendous growth of the API, as represented by the following chart:
The tremendous growth of the API over the last year is due to a combination of the increased number of users, more activity by our users, Netflix’s steady adoption of new devices over time, as well as chattier interfaces to the API.
Growing the API by about 37× in 13 months indicates a few things to us. First, it demonstrates the tremendous success of the API and the fact that it has become a critical system within Netflix. Moreover, it suggests that, because it is so critical, we have to get it right. When reviewing the founding assumptions of the API from 2008, it is now clear to us that the API needs to be redesigned to carry us into the future.
Establishing New Goals
In the two-and-a-half years that the API has been live, some major, fundamental changes have taken place, both with the API and with Netflix. I already mentioned the change in focus from an exclusively public API to one that also drives our device experiences. Additionally, at the time of the launch, Netflix was primarily focused on delivering DVDs. Today, while DVDs are still part of our identity, the growth of our business is streaming. Moreover, we are no longer US-only. In October, we launched in Canada with a pure streaming plan and we are exploring other international markets as well. Because of these fundamental changes, as well as others that have cropped up along the way, the goals of the API have changed. And because the goals have changed, the way the API needs to operate has as well.
Decreasing Total Requests
An example of where the current design is inefficient is in the way the API resources are modeled. Today, there are about 20 resources in the API. Some of these resources are very similar to each other, although they each have their own interfaces and responses. Because of the number of resources and the fact that we are adhering very closely to the REST conventions, our devices need to make a series of calls to the APIs to get all the content needed to render the user interface. The result is that there is a high degree of chattiness between the devices and the APIs. In fact, one of our device implementations accounts for about 50% of the total API calls. That same device, however, is responsible for significantly less streaming traffic. Why is this device so chatty? Can we design our API to reduce the number of calls needed to create the same experience? In essence, assuming everything remains static, could the 20+ billion requests that we handled in January 2011 have been 15 billion? Or 10 billion?
Decreasing Payload
If we reduce the number of requests to the API to achieve the same user experience, it implies that the payload of each request will need to be larger. While it is possible that this extra payload won’t noticeably impair performance, we still would like to reduce the total number of bits delivered. To do so, we will also be looking at ways to handle partial response through the API. Our goal in this approach will be to conceptualize the API as a database. A database can handle incredible variability in requests through SQL. We want the API to be able to answer questions with the same degree of variability that SQL can for a database. Other implementations, like YQL and OData, offer similar flexibility and we will research them as well. Chattiness and payload size (as well as their impact on the request/response model) are just two examples of the things we are researching in our upcoming API redesign. In the coming weeks, as we get deeper into this work, we will continue to post our thinking to this blog.
If these challenges seem exciting to you, we are hiring! Check out the jobs on the API team at our jobs site.
One of the things that I am most commonly asked about regarding the NPR API is rights management. Because we are distributing content to unknown destinations, it is critical to make sure the API itself can control what gets offered and to whom. To handle these kinds of issues, we built a robust permissions and rights management system into the API. But that is not enough. Rights management starts with contracts and ensuring that the content is tagged appropriately. Without these steps, the rights management system cannot accurately withhold the content that is not allowed to be distributed. So, here is a breakdown of the steps we went through and the systems we built to handle rights in our API.
Contracts Before launching the API, we spent a lot of time with our legal team reviewing existing contracts and our rights tagging system. Based on this review, we determined that a few changes needed to be made to the rights tagging system, but there were quite a few restrictions on what could be offered through the API. One interesting example is Fresh Air. Fresh Air is a program produced by WHYY and distributed on the radio by NPR. NPR is also responsible for displaying the content on NPR.org and is allowed to distributed Fresh Air content through limited outlets, like RSS, based on the terms of the contract. At the time of launch, however, NPR was not permitted to offer Fresh Air content through the API using the richer output formats. By the December 2008 upgrade to the API, however, the contract was renegotiated to include distribution through the API.
This highlights two points. First, at launch, we needed to incorporate a rights management system in the API that could identify specific types of content and then restrict that content from being distributed for certain types of users. The second key point is that NPR has been shifting our contract strategy to enable more content that we pick up to be distributable anywhere NPR content appears, including through the API.
Rights Tagging System Our system for tagging assets not produced by NPR is critical for the success of rights management. That said, a sizable portion of this system involves manual effort. After all, it is the editorial process that chooses stories from external sources (e.g. AP, Reuters, etc.), images, videos and other assets. Upon selection of these assets, editorial staff then enter them into our content management system that contains appropriate fields for tagging the owner of the content.
Of course, we do have scripts that pull in some materials, like the AP Business feeds on our site. Those stories and assets that get pulled in through automated systems also get tagged by the scripts.
Finally, we also have scripts to remove content from our system based on contractual obligations. For example, if we have the rights to present an image for only 30 days, these scripts will purge the system of that image and its metadata at the appropriate time.
Rights Management System After we determine what we are allowed to do based on the contracts, and after appropriately tagging the content itself, we were able to create a pretty flexible and powerful system for managing the distribution of the content through the API. This system has four aspects to it, including query-level filtering, story-level filtering, asset-level filtering and user permissions.
Query-level filtering enables the system to remove any story or list (ie. topic, program, series, etc.) from the system due to the permissions. It does this in two ways. First, the system will analyze the API query for any IDs that the user does not have permissions to access. If, for example, the user does not have the rights to view content from This I Believe and the user has included id=4538138 in their API query, the story-level filtering will remove the ID from the query and will proceed to execute the query without it.
Once a valid query passes through the system and figures out what stories to return, the story-level filter gets applied. This filter determines which individual stories need to be removed before returning the feed back to the user. This is done by applying the list of IDs in the filter, for the user’s access level, as exclusions in the query to the API. The list of IDs in the filter include list IDs (eg. topics, programs, series, etc.), so the same rule applies to any stories that belong to any of these lists. For example, we have already established that my API key does not give me permissions to see stories that belong to This I Believe. If I request the top 10 stories that belong to the Opinion topic, and if the third story is a This I Believe story, then the system will eliminate the the third story and will add the eleventh to the results to accommodate my request for 10 stories.
Asset-level filtering is less stringent that story-level filtering in that it does not remove the story completely (as in the example above). Rather, it will display the story, but will only return those assets that the user has the rights to see. For example, if I request the top 10 stories from the People & Places topic, that result set may include a story from Fresh Air and This I Believe. In this case, let’s say story number three is still a This I Believe story and story number seven is a Fresh Air story. We have already established that my API key does not allow me to see This I Believe, so the story-level filter will remove the third story and will include the eleventh in my results. Meanwhile, my API key allows me to see Fresh Air stories, just not all of them (any such restriction is no longer the case, but when we first launched the API, Fresh Air was only available through RSS). As a result, the seventh story will get through the story-level filter, but the asset-level filter will remove all assets other than the RSS information. We have other asset-level filters for audio, images, video, full text, etc.
The final element of this system, which has been mentioned throughout, is permissions. Our permission levels include Public, Partner, Station, NPR.org and Master, with increasing level of access in that order. For each level, there is a distinct list of IDs associated with each filter type (although the query and story filter lists are always the same). As a result, the same story in our system can theoretically be removed for the Public user, only have RSS content for Partner users, have everything but images for Stations, and be fully available to the NPR.org users. Meanwhile, a different story can theoretically have a completely different permission scheme enabling NPR.org users no access to it while public users can see it all.
To see how this filtering layer sits on top of our system, here is an architectural diagram:
Ongoing Challenges Although this system handles our cases for the most part, rights filtering is and will always be a challenge. There are certainly cases that could sneak through the system. These cases could be a result of the editorial process, the tagging tools or the code in the API. We also encounter new scenarios that sometimes require us to quickly modify the API to handle them. Despite these challenges, we have been pretty happy with this system so far.