Content Portability: Building an API is Not Enough
This post first appeared on ProgrammableWeb.com
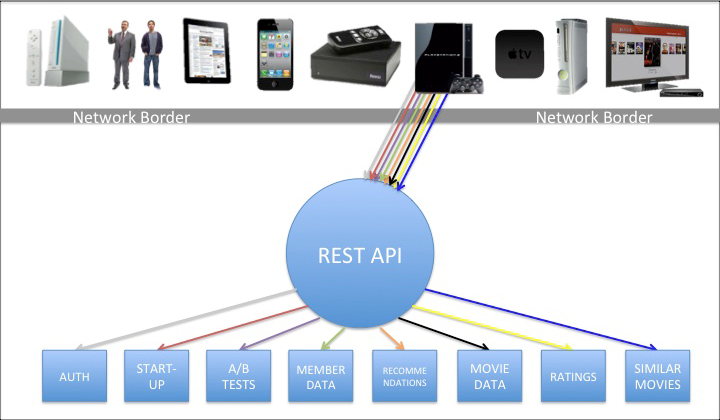
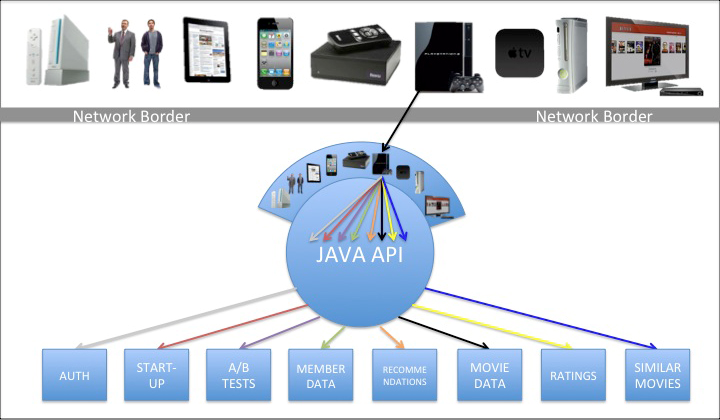
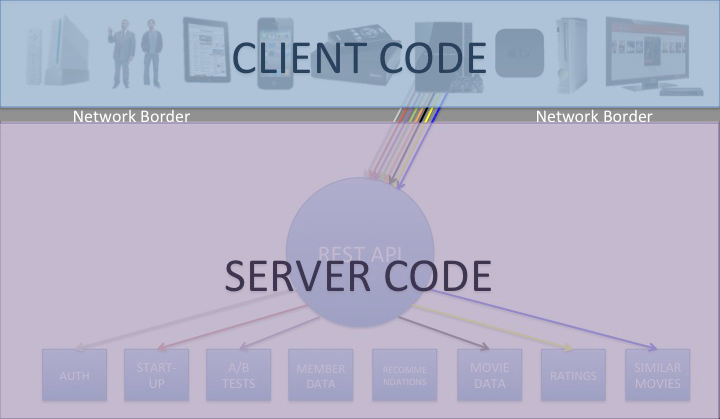
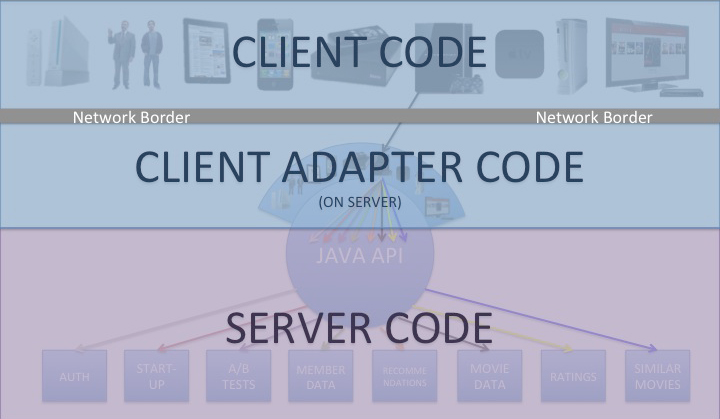
My previous posts focused on COPE (Create Once, Publish Everywhere) and content modularity, the fundamentals for ensuring that content can be managed and distributed to virtually any platform. But ensuring that your content can be delivered to those other platforms does not mean that it can display appropriately on them.
Content often contains very important semantic markup, used to emphasize the content, relate it to other content, describe it, etc. By markup, I mean HTML, character encodings and microformats, among others. Although this markup is important to the content, it also makes it “dirty”, potentially compromising its ability to live and flourish in the myriad places to which it will get distributed. No matter how modular the content is in the database, if it is sullied by this markup, it is not truly portable. As a result, just building an API is not enough. The API needs to be able to distribute the content to any platform in a way that each platform can handle.
To demonstrate this problem around portability, I often use the pre-iPhone iPod as an example. This device did not parse HTML. Rather, tags would simply be printed as strings. When podcasting took off, some NPR titles had HTML tags in them, including < em > and < strong >. Because iPods were not able to render the HTML, titles would like something like, “This is a < em >great< /em > title!” Similar, another fail scenario that is relevant to NPR is an HD Radio display. These devices are also not able to render markup printing these tags to the screen.
There are two primary ways of handling this problem. The more common way is to store the dirty content in the database and to maintain a series of scripts that handle it on the way out. Although this is potentially effective for specific goals, there are some significant problems with it. For starters, stripping out the markup as it gets distributed means that the markup still lives with the content in the database. As a result, as new platforms arise and as markup standards evolve, the markup in the content will remain static. So, each distribution script that handles the markup will need to be carefully maintained and updated accordingly. Moreover, since each distribution platform could have its own compliance with the various forms of markup, each of these outputs may require their own script to handle the content (that is, the more distribution channels there are, the more scripts there are to maintain). Finally, the majority of systems that allow markup in this way do very little to limit the type of markup that is used. Because of the tremendous variance in how the markup is used in the content, these scripts will need to be increasingly complex, causing the accuracy to be tougher to guarantee.
Rather than handling the cleansing process on the way out, NPR has created a system that cleans the content on the way in. The goal here is to save the content in the database in a modular AND portable way. That means that each discrete object type is stored separately while ensuring that text content in each object is devoid of markup. I call this system “Markup Addressing” and here is how it works:
- A range of fields in the system are markup-enabled, allowing Editors and scripts to include HTML and other markup values in the content directly.
- For each field that allows markup, very specific values are allowed. Some fields allow more, some less, but all fields are limited to nothing more than the 25 tags and character encodings that the system as a whole allows.
- We apply client-side handling to ensure that no markup beyond those allowed by the field are used for that field. We also enforce proper nesting and syntax for the markup.
- Before saving the clean and acceptable markup to the database, we identify all markup for each field and begin our “addressing”, which is essentially identifying the character numbers of the markup in the text. For each tag or character identified, we find the character position for where it starts. If applicable, we also find the character position for the close tag. We then strip out the markup from the text and store in a relational table the address in the text that the markup was found.
- This relational table does not include the markup itself. Rather, that is stored in a separate table that is the authority for which tags are allowable. The image below represents roughly how we store this kind of information.

- The diagram above represents how NPR strips out markup from content fields prior to saving to the database. The markup is then “addressed” and stored in a series of relational tables, enabling any presentation layer to present the content with or without markup. It even allows the markup to be easily transformed as needed before pushing to different platforms. (Click here for an enlargement of this diagram)
There are several very tangible benefits to this approach, all of which improve overall portability of the content. These benefits include:
- Distributing the content without any markup is as simple as pushing out the content from the database directly, without any further processing. This is helpful for platforms that are unable to render markup, including those mentioned in my examples above.
- Distributing the content with the original markup is just as easy by reassembling the markup based on the addresses.
- It is easy to only distribute only some of the markup based on what the markup is. An example of this is if the destination product wants to emphasize content but does not want to allow for links to other content.
- As markup, such as HTML tags, get deprecated, this approach only requires a change to one field in the entire database, instead of having to cycle through the database to find all instances of the old tag to replace it with the new one. For example, < b > has been replaced with < strong >, so we simply need to modify the one record in the authority table for tags to make this change apply across the entire set of content.
- As new platforms arise, if they require specialized markup, it is easy to transform the existing markup to anything else required for these new platforms.
- Adding new allowable tags is easy by simply extending the client-side handling and the authority table. These tags can include microformats and other business-critical tags that help describe the content. For example, NPR could very easily create a tag for our internal purposes for < station >, such that for every station that gets tagged, rather than rendering this tag, the system will look up the station in our database and replace that < station > tag with a hyperlink to the station’s home page.
NPR’s system applies these methods to specific fields throughout our CMS. When distributing the content through the API, however, we only currently apply the power of Markup Addressing to the story full text. The API has a field for < text > which removes all markup for the syndication as well as < textWithHtml > which reassembles the content with all markup. Extending this to all other markup-enabled fields would be quite easy under this system, although there has not yet been a need to do so.
Regardless of which approach is taken, there is one other significant issue that prevents true portability of content… the content itself!
I create a distinction between “content” and “calls-to-action” to help clarify this problem. Content is the information that the users actually want to consume. It could also include metadata, which helps to accurately describe the content that the user is actually consuming. Within this content, applying markup that emphasizes it or relates it to other content should be done in such a way that the meaning of the content is unaltered by the abstraction of the markup from the content. Here is an example of an appropriate way to apply markup to the content:

This image is part of an NPR story that demonstrates appropriate use of HTML within the body of the text. The artists’ names are linking to artist pages, but the meaning of the story is completely unaltered by the removal of the markup.
In this scenario, removing the links to the artists’ names in the text, for example, does not alter the meaning of the content. Of course, it does diminish some of its power as the user cannot easily learn more about these artists within the context of this story. That said, distribution of this content without those links will not adversely affect the meaning of the story. The artist names are valid and appropriate within the body of the text.
Applying markup within the content that is calling the users to perform an action, on the other hand, poses a different problem. Here is an example of a call-to-action within the content:

This image is part of the same NPR story demonstrating the use of calls-to-action, which make the content unable to provide meaning without the context of the markup. These calls-to-action make the content less portable, specifically to platforms that are not markup enabled.
Notice that within this content there is a link to related content where the link text is “Listen to The Entire Album”. Abstracting away the link itself actually alters the meaning of the text as the text provides no information about the audio asset. There is no indication as to what album or who the artist is. So, as this content gets distributed to platforms (both known and unknown), pulling out the markup actually adversely affects the content.
This is a problem for every content producer, including NPR. Although we have gone through great measures to put the content in the best position to live and thrive in all platforms, there is still work to be done to ensure the success of our distribution strategies. Some of these efforts are technical in nature. Others could impact editorial processes and style guides. But in all cases, our goals are the same… to be a media organization that produces great content for our users, wherever they wish to consume it.
![]() APIs, Content Management, COPE, Engineering, NPR, Technology
|
APIs, Content Management, COPE, Engineering, NPR, Technology
| ![]() API, CMS, COPE, NPR, Portability
API, CMS, COPE, NPR, Portability