Presentation : NPR at Wolfram Data Summit 2010
This presentation was given at the Wolfram Data Summit in September of 2010, focusing on content management, APIs and COPE.
This presentation was given at the Wolfram Data Summit in September of 2010, focusing on content management, APIs and COPE.
This post (originally appearing in ProgrammableWeb.com, which is now defunct) comes from Daniel Jacobson, Director of Application Development for NPR. Daniel leads NPR’s content management solutions, is the creator of the NPR API and is a frequent contributor to the Inside NPR.org blog.
One of the questions that I am most frequently asked regarding content APIs is “how can I make money with my API?” Before answering that question, however, it is important to ask for whom the API is designed. After all, the audiences for your API will determine what business opportunities exist.
The most common target audience for APIs is the developer community. While that audience is an interesting and potentially important one, it is not where the greatest value can be realized.
When we launched the NPR API in 2008, we established four target audiences, each of which were important. The target audiences were (and still are):
With the API live for a full two years, I decided to look more closely at how effectively the API has been serving these four audiences. Although I am not surprised by the results, you may be…
The following charts show the distribution of how many API keys are registered by each of our four audiences. That metric is then compared to the consumption of the API (as measured by API requests) by the four audiences:
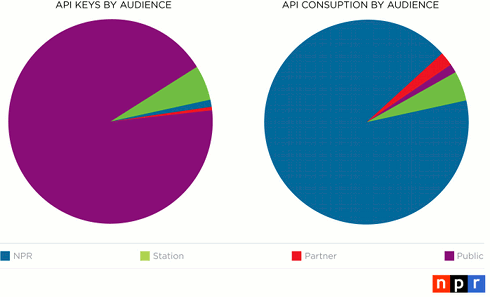
Obviously, there are many more API keys registered to the general public than the others. In fact, our API currently has over 10 times more public keys than all other keys in the system combined.
Despite the disparity between public keys and those used by other audiences, the dominant group from a request perspective is overwhelmingly NPR, responsible for more than 92% of the total number of requests. That means that the remaining 8% of requests are coming from all three other target audiences combined.
When considering this distribution in requests by audience relative to the key distribution by audience, it is clear that NPR has by far been the most effective user of the API. So, given the incredible amount of consumption by NPR, how has that translated into revenue opportunities? Below is a chart detailing the growth in total page views across all NPR platforms over a twelve-month span:
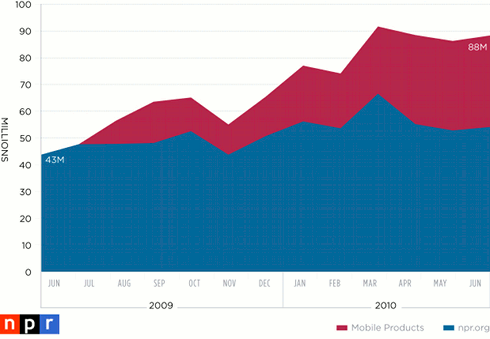
By the end of the twelve months, NPR’s total page view growth has increased by more than 100%. How were we able to add that many page views in such a short amount of time? The API. Not directly. But the API did enable NPR product owners to quickly, efficiently and independently build specialized apps in various new platforms. As a result, what we have seen is primarily additive growth. In other words, in addition to NPR.org’s growth (by about 19%), we have been able to add the NPR News iPhone app, the improved mobile site, the Android app, the iPad app, etc., each of which adds page views. From our analysis, adding these new platforms is generating new traffic and is not cannibalizing page views from NPR.org in a substantive way. These new page views create new sponsorship/advertising inventory that create new revenue opportunities.
So, when asked the question “how can I make money with my content API?”, the answer should always be based on your target audiences. And from NPR’s experience, the best way to make money is to focus on how the API can improve your internal processes. Of course, it is still important to maintain a solid support and growth model for the other audiences as well, but we cannot all be Google, Netflix, Twitter, etc. Unless you are planning to spend a lot of money on community engagement, you are better served by making sure you can liberate your product owners and grow your business more quickly, efficiently and independently.
In other words, don’t assume that the API’s primary audience is the developer community. Question that default position and do the introspection that will enable you to get the maximum value out of your API.
I originally published this post to Inside NPR.org on June 8, 2009
One of the things that I am most commonly asked about regarding the NPR API is rights management. Because we are distributing content to unknown destinations, it is critical to make sure the API itself can control what gets offered and to whom. To handle these kinds of issues, we built a robust permissions and rights management system into the API. But that is not enough. Rights management starts with contracts and ensuring that the content is tagged appropriately. Without these steps, the rights management system cannot accurately withhold the content that is not allowed to be distributed. So, here is a breakdown of the steps we went through and the systems we built to handle rights in our API.
Contracts
Before launching the API, we spent a lot of time with our legal team reviewing existing contracts and our rights tagging system. Based on this review, we determined that a few changes needed to be made to the rights tagging system, but there were quite a few restrictions on what could be offered through the API. One interesting example is Fresh Air. Fresh Air is a program produced by WHYY and distributed on the radio by NPR. NPR is also responsible for displaying the content on NPR.org and is allowed to distributed Fresh Air content through limited outlets, like RSS, based on the terms of the contract. At the time of launch, however, NPR was not permitted to offer Fresh Air content through the API using the richer output formats. By the December 2008 upgrade to the API, however, the contract was renegotiated to include distribution through the API.
This highlights two points. First, at launch, we needed to incorporate a rights management system in the API that could identify specific types of content and then restrict that content from being distributed for certain types of users. The second key point is that NPR has been shifting our contract strategy to enable more content that we pick up to be distributable anywhere NPR content appears, including through the API.
Rights Tagging System
Our system for tagging assets not produced by NPR is critical for the success of rights management. That said, a sizable portion of this system involves manual effort. After all, it is the editorial process that chooses stories from external sources (e.g. AP, Reuters, etc.), images, videos and other assets. Upon selection of these assets, editorial staff then enter them into our content management system that contains appropriate fields for tagging the owner of the content.
Of course, we do have scripts that pull in some materials, like the AP Business feeds on our site. Those stories and assets that get pulled in through automated systems also get tagged by the scripts.
Finally, we also have scripts to remove content from our system based on contractual obligations. For example, if we have the rights to present an image for only 30 days, these scripts will purge the system of that image and its metadata at the appropriate time.
Rights Management System
After we determine what we are allowed to do based on the contracts, and after appropriately tagging the content itself, we were able to create a pretty flexible and powerful system for managing the distribution of the content through the API. This system has four aspects to it, including query-level filtering, story-level filtering, asset-level filtering and user permissions.
Query-level filtering enables the system to remove any story or list (ie. topic, program, series, etc.) from the system due to the permissions. It does this in two ways. First, the system will analyze the API query for any IDs that the user does not have permissions to access. If, for example, the user does not have the rights to view content from This I Believe and the user has included id=4538138 in their API query, the story-level filtering will remove the ID from the query and will proceed to execute the query without it.
Once a valid query passes through the system and figures out what stories to return, the story-level filter gets applied. This filter determines which individual stories need to be removed before returning the feed back to the user. This is done by applying the list of IDs in the filter, for the user’s access level, as exclusions in the query to the API. The list of IDs in the filter include list IDs (eg. topics, programs, series, etc.), so the same rule applies to any stories that belong to any of these lists. For example, we have already established that my API key does not give me permissions to see stories that belong to This I Believe. If I request the top 10 stories that belong to the Opinion topic, and if the third story is a This I Believe story, then the system will eliminate the the third story and will add the eleventh to the results to accommodate my request for 10 stories.
Asset-level filtering is less stringent that story-level filtering in that it does not remove the story completely (as in the example above). Rather, it will display the story, but will only return those assets that the user has the rights to see. For example, if I request the top 10 stories from the People & Places topic, that result set may include a story from Fresh Air and This I Believe. In this case, let’s say story number three is still a This I Believe story and story number seven is a Fresh Air story. We have already established that my API key does not allow me to see This I Believe, so the story-level filter will remove the third story and will include the eleventh in my results. Meanwhile, my API key allows me to see Fresh Air stories, just not all of them (any such restriction is no longer the case, but when we first launched the API, Fresh Air was only available through RSS). As a result, the seventh story will get through the story-level filter, but the asset-level filter will remove all assets other than the RSS information. We have other asset-level filters for audio, images, video, full text, etc.
The final element of this system, which has been mentioned throughout, is permissions. Our permission levels include Public, Partner, Station, NPR.org and Master, with increasing level of access in that order. For each level, there is a distinct list of IDs associated with each filter type (although the query and story filter lists are always the same). As a result, the same story in our system can theoretically be removed for the Public user, only have RSS content for Partner users, have everything but images for Stations, and be fully available to the NPR.org users. Meanwhile, a different story can theoretically have a completely different permission scheme enabling NPR.org users no access to it while public users can see it all.
To see how this filtering layer sits on top of our system, here is an architectural diagram:

Ongoing Challenges
Although this system handles our cases for the most part, rights filtering is and will always be a challenge. There are certainly cases that could sneak through the system. These cases could be a result of the editorial process, the tagging tools or the code in the API. We also encounter new scenarios that sometimes require us to quickly modify the API to handle them. Despite these challenges, we have been pretty happy with this system so far.
Derek Gottfrid Speaking at OSCON Thursday. Photo Courtesy James Duncan Davidson/O’Reilly Media Is the future of news in the hands of internet developers? News organizations New York Times and National Public Radio (NPR) think so. O’Reilly Open Source Convention (OSCON) this week offers the opportune time for NPR and New York Times programmers to discuss […]
O’Reilly Open Source Convention (OSCON) this week offers the opportune time for NPR and New York Times programmers to discuss the release of their news source Application Programming Interfaces (APIs).
NPR’s announcement came earlier in the week. NPR’s API introduces the ability to write applications surrounding public radio’s text and audio from most radio programs dating back to 1995. It was only a matter of days before Phoenix programmer John Tynan exemplified what one can do with the API by mashing up NPR headlines with a Simile Timeline visualization.
Likewise, New York Times programmer Derek Gottfrid is excited about his API. Officially on the menu: public-ready releases of some of the APIs they’ve used internally. First out of the gate later this year will be read-only APIs in distinct content segments, like movie reviews, restaurant reviews and wedding announcements.
Both APIs follow Reuter’s lead: The news agency released its API in May. If the APIs take off, soon all major global news organizations will be offering audiences ways to craft their own presentations of what the news is and what it looks like on the Web.
Wired.com took Dan Jacobson from NPR and Derek Gottfrid from the New York Times to a Portland restaurant to talk about their company’s news APIs.
Wired.com: What do you say when people ask you what an API is?
Dan Jacobson from NPR: We’ve been spending a lot of time in front of lots of people explaining what we’re doing. It is a challenging topic for people who don’t understand it. Basically we’ve been saying it’s like an implicit handshake between two applications, or two computer systems, or whatever.
Derek Gottfrid from The New York Times: It really is just another syndication mechanism for us. That data that you, an API user, have. Because it’s [in a] semi-structured form, it allows it to show up in different places – in applications, in different places around our website, in different places around the web in general.
Wired.com: So your people know what RSS syndication is. Can you leverage that to explain things?
Gottfrid: When we talk about syndication, it’s something that, for a newspaper, has been part of the business vernacular for a long time. So it’s distribution. It’s the same notion as distribution, or influence… Part of The New York Times mission is to create, collect and distribute high-quality news, information and entertainment. “Distribute” is analogous to syndication. I think the terms have a natural flow to people in the organization.
Wired.com: What makes your API special? How do you expect people to use it?
Gottfrid: What makes it special is the data it accesses, right? It’s not the format and whether it is XML or JSON or anything like that. For the format part, we want to just follow best practices of the community. It’s really access to all the interesting data, whether that’s all the recipes that have been in the paper, or all the news articles about particular topics, or weddings, or events or whatever data that we’ve accumulated over the years. I think that the data is really the interesting part, and that’s the unique part that we have. That is a differentiator.
Wired.com: So The New York Times API will be able to go back in time through the entire historical archives of the paper?
Gottfrid: We have the data, so creating APIs around it is done internally all the time. Making them so they’re consumable by the outside world requires additional effort, and that’s really where we are. We have all this data. We’re familiar with it. We’re trying to make it as palatable, and as easy as possible for outside folks to get at it is really the next step that we’re working on.
Jacobson: I agree completely. It’s all about the content. If you don’t have compelling content, then no matter how sweet the application is nobody’s going to want to come and get it. I think that NPR, like The New York Times, offers a rich, unique spin on the content we provide. In terms of the functionality of the API, one of the interesting things we’re offering is a very comprehensive way of slicing through the data. If you go to NPR.org, for example, you’re getting NPR’s presentation of our data. It’s our compilations and our topic structures. Through the API, users can come and slice the content however they want it, create their own custom feeds and we’ll leave it up to them to build exactly what they want. Things we couldn’t even envision.
Wired.com: NPR has an affiliate network that The New York Times doesn’t have. Does the API stand to affect the dynamic between National Public Radio and its affiliates?
Jacobson: There are two sweet spots for the API: It fits NPR’s public service mission to help people be better informed, enabling users to get our content in a variety of ways – however, they want it. For the stations, it lets us get local station content in and then feed it back out through the API, which we’re doing some of already. But it also enables the stations to represent to their communities whatever they want. They can mash up local and national content. Or their users can do the same in ways that, prior to the API, they couldn’t do.
Wired.com: Does The New York Times have intermediaries it’s looking to serve with your API?
Gottfrid: We’re geared to whoever is going to find the content interesting. Anyone that’s interested in it, we’re interested in making it accessible and having them use it. This isn’t something that’s driven off of market research or anything like that. This is fulfilling a basic gut-level instinct that this is how the internet works.
Wired.com: Where does that gut-level instinct come from? Is it a matter of transforming internal work processes and extending them?
Gottfrid: Yeah, it’s a natural outgrowth. As we’ve become more sophisticated, we’ve taken more of a platform and service architecture [approach] to a lot of the things we do so that we can re-use them and mix them and mash them for our own site. I think [The New York Times API] is the natural extension. It flows into a lot of things that we see in terms of opening up to the broader web. Really going from being “on the internet” to being “part of the internet” – intermingling our stuff with the full experience of things around the internet.
Wired.com: Where does NPR fall on the internal versus external utility of its API? Was it developed specifically with external users in mind?
Jacobson: The evolution of our API was pretty organic. We built an API to support NPR.org, and launched that in November of 2007. Our site’s been running on the API for that long. The natural next step was to say, ‘Wait a minute. Why can’t we just put this out there.’ What do we need to do in order to open this up and satisfy … users’ goals with YouTube and Google Maps and the way they’re able to reach new audiences. Then it became a policy question as we sat down with a range of stakeholders and figured out what we are allowed to do. Turns out we’re allowed to distribute through the API everything that we have the rights to (which isn’t everything you hear on NPR stations).
Gottfrid: The technology people sit at the nexus of [our audience] so we facilitate an interchange between [them]. Clearly we need to be able to do stuff with our content management to support the reporting efforts. Our end users, well we wouldn’t be here without the readers. It’s a continual balancing act, especially when online readers aren’t as remote as they are with the printed product. There’s a different relationship that we’re establishing.
Jacobson: I think Derek said something really interesting, implying that technology is also a stakeholder in the kinds of things that happen. This API project, for example, is something that we drove. We became a stakeholder because this is a project that we wanted to release, which is somewhat tied to the business goals. Making the case that we need to do this is convincing the business people that, yes, we need to do this.
[Interview by Brad Stenger]
![]() APIs, NPR, Presentation, Technology
|
APIs, NPR, Presentation, Technology
| ![]() OSCON, Wired.com
OSCON, Wired.com
Panorama Theme by ![]() Themocracy
Themocracy