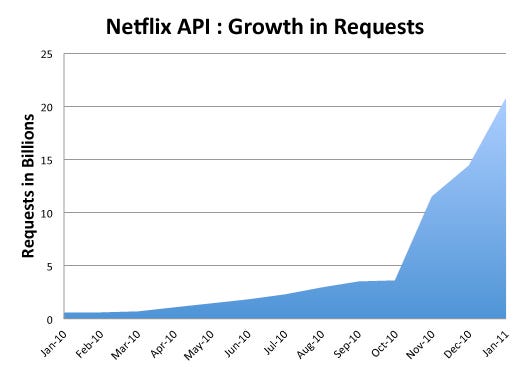
This is Daniel Jacobson, Director of Engineering for the API here at Netflix. The Netflix API launched in 2008 with a focus on the public developer community. The expectation was that this community would build amazing and inspiring applications that would take Netflix to a new level in serving our members. While some fantastic things were built by this community, including sites like Instant Watcher, the transformational moment for the API was when we started to use it to deliver the streaming functionality to Netflix ready devices. In the last year, we have escalated this approach to deliver Netflix metadata through the API to hundreds of devices. All of this has culminated in tremendous growth of the API, as represented by the following chart:
The tremendous growth of the API over the last year is due to a combination of the increased number of users, more activity by our users, Netflix’s steady adoption of new devices over time, as well as chattier interfaces to the API.
Growing the API by about 37× in 13 months indicates a few things to us. First, it demonstrates the tremendous success of the API and the fact that it has become a critical system within Netflix. Moreover, it suggests that, because it is so critical, we have to get it right. When reviewing the founding assumptions of the API from 2008, it is now clear to us that the API needs to be redesigned to carry us into the future.
Establishing New Goals
In the two-and-a-half years that the API has been live, some major, fundamental changes have taken place, both with the API and with Netflix. I already mentioned the change in focus from an exclusively public API to one that also drives our device experiences. Additionally, at the time of the launch, Netflix was primarily focused on delivering DVDs. Today, while DVDs are still part of our identity, the growth of our business is streaming. Moreover, we are no longer US-only. In October, we launched in Canada with a pure streaming plan and we are exploring other international markets as well. Because of these fundamental changes, as well as others that have cropped up along the way, the goals of the API have changed. And because the goals have changed, the way the API needs to operate has as well.
Decreasing Total Requests
An example of where the current design is inefficient is in the way the API resources are modeled. Today, there are about 20 resources in the API. Some of these resources are very similar to each other, although they each have their own interfaces and responses. Because of the number of resources and the fact that we are adhering very closely to the REST conventions, our devices need to make a series of calls to the APIs to get all the content needed to render the user interface. The result is that there is a high degree of chattiness between the devices and the APIs. In fact, one of our device implementations accounts for about 50% of the total API calls. That same device, however, is responsible for significantly less streaming traffic. Why is this device so chatty? Can we design our API to reduce the number of calls needed to create the same experience? In essence, assuming everything remains static, could the 20+ billion requests that we handled in January 2011 have been 15 billion? Or 10 billion?
Decreasing Payload
If we reduce the number of requests to the API to achieve the same user experience, it implies that the payload of each request will need to be larger. While it is possible that this extra payload won’t noticeably impair performance, we still would like to reduce the total number of bits delivered. To do so, we will also be looking at ways to handle partial response through the API. Our goal in this approach will be to conceptualize the API as a database. A database can handle incredible variability in requests through SQL. We want the API to be able to answer questions with the same degree of variability that SQL can for a database. Other implementations, like YQL and OData, offer similar flexibility and we will research them as well. Chattiness and payload size (as well as their impact on the request/response model) are just two examples of the things we are researching in our upcoming API redesign. In the coming weeks, as we get deeper into this work, we will continue to post our thinking to this blog.
If these challenges seem exciting to you, we are hiring! Check out the jobs on the API team at our jobs site.
As I discussed in my recent blog post on ProgrammableWeb.com, Netflix has found substantial limitations in the traditional one-size-fits-all (OSFA) REST API approach. As a result, we have moved to a new, fully customizable API. The basis for our decision is that Netflix’s streaming service is available on more than 800 different device types, almost all of which receive their content from our private APIs. In our experience, we have realized that supporting these myriad device types with an OSFA API, while successful, is not optimal for the API team, the UI teams or Netflix streaming customers. And given that the key audiences for the API are a small group of known developers to which the API team is very close (i.e., mostly internal Netflix UI development teams), we have evolved our API into a platform for API development. Supporting this platform are a few key philosophies, each of which is instrumental in the design of our new system. These philosophies are as follows:
Embrace the Differences of the Devices
Separate Content Gathering from Content Formatting/Delivery
Redefine the Border Between “Client” and “Server”
Distribute Innovation
I will go into more detail below about each of these, including our implementation and what the benefits (and potential detriments) are of this approach. However, each philosophy reflects our top-level goal: to provide whatever is best for the Netflix customer. If we can improve the interaction between the API and our UIs, we have a better chance of making more of our customers happier.
Now, the philosophies…
Embrace the Differences of the Devices
The key driver for this redesigned API is the fact that there are a range of differences across the 800+ device types that we support. Most APIs (including the REST API that Netflix has been using since 2008) treat these devices the same, in a generic way, to make the server-side implementations more efficient. And there is good reason for this approach. Providing an OSFA API allows the API team to maintain a solid contract with a wide range of API consumers because the API team is setting the rules for everyone to follow.
While effective, the problem with the OSFA approach is that its emphasis is to make it convenient for the API provider, not the API consumer. Accordingly, OSFA is ignoring the differences of these devices; the differences that allow us to more optimally take advantage of the rich features offered on each. To give you an idea of these differences, devices may differ on:
Memory capacity or processing power, potentially modifying how much content it can manage at a given time
Requirements for distinct markup formats and broader device proliferation increases the likelihood of this
Document models, some devices may perform better with flatter models, others with more hierarchical
Screen real estate which may impact the content elements that are needed
Document delivery, some performing better with bits streamed across HTTP rather than delivered as a complete document
User interactions, which could influence the metadata fields, delivery method, interaction model, etc.
Our new model is designed to cut against the OSFA paradigm and embrace the differences across devices while supporting those differences equally. To achieve this, our API development platform allows each UI team to create customized endpoints. So the request/response model can be optimized for each team’s UIs to account for unique or divergent device requirements. To support the variability in our request/response model, we need a different kind of architecture, which takes us to the next philosophy…
Separate Content Gathering from Content Formatting/Delivery
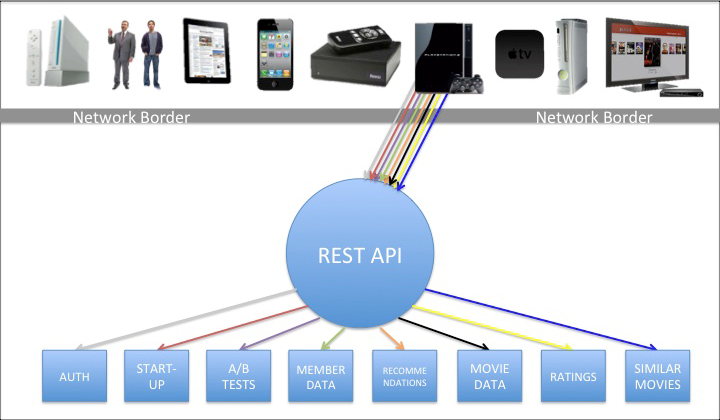
In many OSFA implementations, the API is the engine that retrieves the content from the source(s), prepares that payload, and then ultimately delivers it. Historically, this implementation is also how the Netflix REST API has operated, which is loosely represented by the following image:
The above diagram shows a rainbow of colors roughly representing some of the different requests needed for the PS3, as an example, to start the Netflix experience. Other UIs will have a similar set of interactions against the OSFA REST API given that they are all required by the API to adhere to roughly the same set of rules. Inside the REST API is the engine that performs the gathering, preparation and delivery of the content (indifferent to which UI made the request).
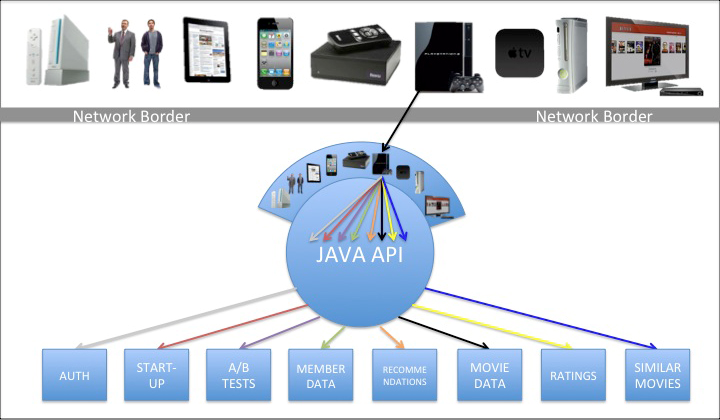
Our new API has departed from the OSFA API model towards one that enables fine-grained customizations without compromising overall system manageability. To achieve this model, our new architecture clearly separates the operations of content gathering from content formatting and delivery. The following diagram represents this modified architecture:
In this new model, the UIs make a single request to a custom endpoint that is designed to specifically handle that request. Behind the endpoint is a handler that parses the request and calls the Java API, which gathers the content by calling back to a range of dependent services. We will discuss in later posts how we do this, particularly in how we parse the requests, trigger calls to dependencies, handle concurrency, support fallbacks, as well as other techniques we use to ensure optimized and accurate gathering of the content. For now, though, I will just say that the content gathering from the Java API is generic and independent of destination, just like the OSFA approach.
After the content has been gathered, however, it is handed off to the formatting and delivery engines which sit on top of the Java API on the server. The diagram represents this layer by showing an array of different devices resting on top of the Java API, each of which corresponds to the custom endpoints for a given UI and/or set of devices. The custom endpoints, as mentioned earlier, support optimized request/response handling for that device, which takes us to the next philosophy…
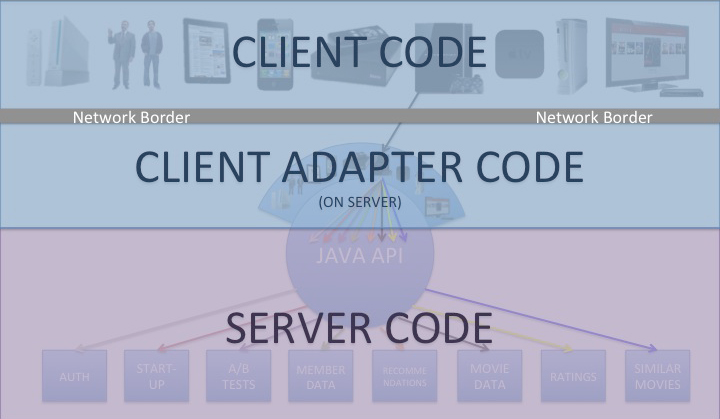
Redefine the Border Between “Client” and “Server”
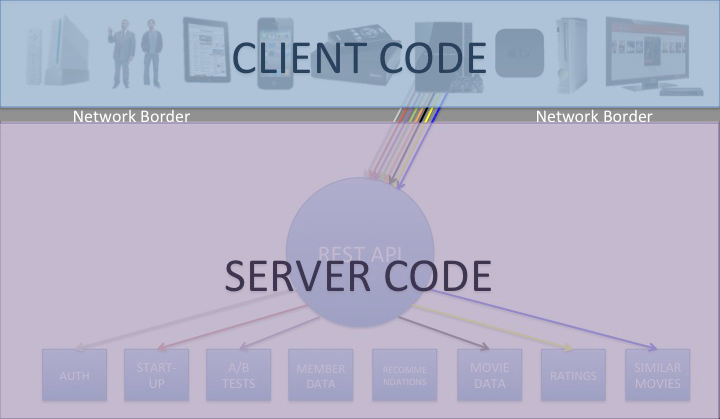
The traditional definition of “client code” is all code that lives on a given device or UI. “Server code” is typically defined as the code that resides on the server. The divide between the two is the network border. This is often the case for REST APIs and that border is where the contract between the API provider and API consumer is engaged, as was the case for Netflix’s REST API, as shown below:
In our new approach, we are pushing this border back to the server, and with it goes a substantial portion of the UI-specific content processing. All of the code on the device is still considered client code, but some client code now resides on the server. In essence, the client code on the device makes a network call back to a dedicated client adapter that resides on the server behind the custom endpoint. Once back on the server, the adapter (currently written in Groovy) explodes that request out to a series of server-side calls that get the corresponding content (in some cases, roughly the same rainbow of requests that would be handled across HTTP in our old REST API). At that point, the Java APIs perform their content gathering functions and deliver the requested content back to the adapter. Once the adapter has some or all of its content, the adapter processes it for delivery, which includes pruning out unwanted fields, error handling and retries, formatting the response, and delivering the document header and body. All of this processing is custom to the specific UI. This new definition of client/server is represented in the following diagram:
There are two major aspects to this change. First, it allows for more efficient interactions between the device and the server since most calls that otherwise would be going across the network can be handled on the server. Of course, network calls are the most expensive part of the transaction, so reducing the number of network requests improves performance, in some cases by several seconds. The second key component leads us to the final (and perhaps most important) philosophy to this approach, which is the distribution of the work for building out the optimized adapters.
Distribute Innovation
One expected critique with this approach is that as we add more devices and build more UIs for A/B and multivariate tests, there will undoubtedly be myriad adapters needed to support all of these distinct request profiles. How can we innovate rapidly and support such a diverse (and growing) set of interactions? It is critical for us to support the custom adapters, but it is equally important for us to maintain a high rate of innovation across these UIs and devices.
As described above, pushing some of the client code back to the servers and providing custom endpoints gives us the opportunity to distribute the API development to the UI teams. We are able to do this because the consumers of this private API are the Netflix UI and device teams. Given that the UI teams can create and modify their own adapter code (potentially without any intervention or involvement from the API team), they can be much more nimble in their development. In other words, as long as the content is available in the Java API, the UI teams can change the code that lives on the device to support the user experience and at the same time change the adapter code to deliver the payload needed for that experience. They are no longer bound by server teams dictating the rules and/or being a bottleneck for their development. API innovation is now in the hands of the UI teams! Moreover, because these adapters are isolated from each other, this approach also diminishes the risk of harming other device implementations with tactical changes in their device-specific APIs.
Of course, one drawback to this is that UI teams are often more skilled in technologies like HTML5, CSS3, JavaScript, etc. In this system, they now need to learn server-side technologies and techniques. So far, however, this has been a relatively small issue, especially since our engineering culture is to hire very strong, senior-level engineers who are adaptable, curious and passionate about learning and implementing these kinds of solutions. Another concern is that because the UI teams are implementing server-side adapters, they have the potential to bring down the servers through infinite loops or other processes that are resource intensive. To offset this, we are working on scrubbing engines that will hopefully minimize the likelihood of such mistakes. That said, in the OSFA world, code on the device can just as easily DDOS the server, it is just potentially a bigger problem if it runs on the server.
Example of how this new system works:
A device, such as the PS3, makes a single request across the network to load the home screen (This code is written and supported by the PS3 UI team.
A Groovy adapter receives and parses the PS3 request (PS3 UI team)
The adapter explodes that one request into many requests that call the Java API to (PS3 UI team)
Each Java API calls back to a dependent service, concurrently when appropriate, to gather the content needed for that sub-request (API team)
In the Java API, if a dependent service unavailable or returns a 4xx or 5xx, the Java API returns a fallback and/or an error code to the adapter (API team)
Successful Java API transactions then return the content back to the adapter when each thread has completed (API team)
The adapter can handle the responses from each thread progressively or all together, depending on how the UI team wants to handle it (PS3 UI team)
The adapter then manipulates the content, retrieves the wanted (and prunes out the unwanted) elements, handle errors, etc. (PS3 UI team)
The adapter formats the response in preparation for delivery back across the network to the PS3, which includes everything needed for the PS3 home screen in the single payload (PS3 UI team)
The adapter finally handles the delivery of the payload across the network (PS3 UI team)
The device will then parse this optimized response and populate the UI (PS3 UI team)
We are still in the early stages of this new system. Some of our devices have fully migrated over to it, others are split between it and the REST API, and others are just getting their feet wet. In upcoming posts, we will share more about the deeper technical aspects of the system, including the way we handle concurrency, how we manage the adapters, the interaction between the adapters and the Java API, our Groovy implementation, error handling, etc. We will also continue to share the evolution of this system as we learn more about it.
This post (originally appearing in ProgrammableWeb.com, which is now defunct) comes from Daniel Jacobson, Director of Application Development for NPR. Daniel leads NPR’s content management solutions, is the creator of the NPR API and is a frequent contributor to the Inside NPR.org blog.
One of the questions that I am most frequently asked regarding content APIs is “how can I make money with my API?” Before answering that question, however, it is important to ask for whom the API is designed. After all, the audiences for your API will determine what business opportunities exist.
The most common target audience for APIs is the developer community. While that audience is an interesting and potentially important one, it is not where the greatest value can be realized.
When we launched the NPR API in 2008, we established four target audiences, each of which were important. The target audiences were (and still are):
NPR: NPR is of highest importance because as we build all of our systems, mobile apps, etc., it was important to be as nimble and efficient as possible. We have adopted this so deeply that the API is the foundation of everything that we do, including acting as the content source to NPR.org.
NPR member stations: NPR member stations are a critical aspect of the NPR mission and business model. Offering the stations a new, more effective way to get NPR content in a robust way better serves the stations and their communities, as well as NPR.
NPR partners: Having the API quickly became a more effective way to interact with content aggregators, business partners and other commercial entities with whom we established relationships. In fact, the API became a business development tool where some external organizations approached us because we had a robust API.
the general public: Finally, as part of our public service mission, it was and is important for NPR to share our content with the world. Exposing it to the developer community is a natural extension of this effort. But when we launched the API, we fully expected this to be where true innovation took place with the API. In fact, the day after our launched, I told CNet that the community of “developers will come up with a lot of brilliant ideas.”
With the API live for a full two years, I decided to look more closely at how effectively the API has been serving these four audiences. Although I am not surprised by the results, you may be…
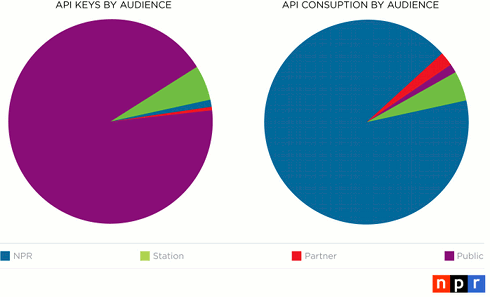
The following charts show the distribution of how many API keys are registered by each of our four audiences. That metric is then compared to the consumption of the API (as measured by API requests) by the four audiences:
Obviously, there are many more API keys registered to the general public than the others. In fact, our API currently has over 10 times more public keys than all other keys in the system combined.
Despite the disparity between public keys and those used by other audiences, the dominant group from a request perspective is overwhelmingly NPR, responsible for more than 92% of the total number of requests. That means that the remaining 8% of requests are coming from all three other target audiences combined.
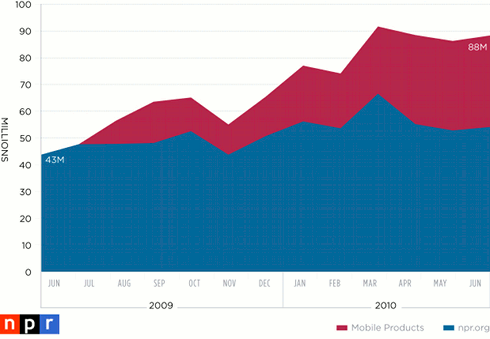
When considering this distribution in requests by audience relative to the key distribution by audience, it is clear that NPR has by far been the most effective user of the API. So, given the incredible amount of consumption by NPR, how has that translated into revenue opportunities? Below is a chart detailing the growth in total page views across all NPR platforms over a twelve-month span:
By the end of the twelve months, NPR’s total page view growth has increased by more than 100%. How were we able to add that many page views in such a short amount of time? The API. Not directly. But the API did enable NPR product owners to quickly, efficiently and independently build specialized apps in various new platforms. As a result, what we have seen is primarily additive growth. In other words, in addition to NPR.org’s growth (by about 19%), we have been able to add the NPR News iPhone app, the improved mobile site, the Android app, the iPad app, etc., each of which adds page views. From our analysis, adding these new platforms is generating new traffic and is not cannibalizing page views from NPR.org in a substantive way. These new page views create new sponsorship/advertising inventory that create new revenue opportunities.
So, when asked the question “how can I make money with my content API?”, the answer should always be based on your target audiences. And from NPR’s experience, the best way to make money is to focus on how the API can improve your internal processes. Of course, it is still important to maintain a solid support and growth model for the other audiences as well, but we cannot all be Google, Netflix, Twitter, etc. Unless you are planning to spend a lot of money on community engagement, you are better served by making sure you can liberate your product owners and grow your business more quickly, efficiently and independently.
In other words, don’t assume that the API’s primary audience is the developer community. Question that default position and do the introspection that will enable you to get the maximum value out of your API.
This article was first published on The Next Web on March 25, 2014
Daniel Jacobson (LinkedIn) is the VP of Edge Engineering for the NetflixAPI. Prior to Netflix, Daniel ran application development for NPR where, among other things, he created the NPR API. He is also the co-author of APIs: A Strategy Guide.
Building great engineering teams is difficult, but it is also increasingly important as the world in which we live is more than ever driven by software. Because of this growing importance, it is essential for engineering leaders to maintain a culture of innovation within their teams to ensure high performance and to keep the company ahead of the curve.
In high performance cultures like at Netflix, there are basically two outcomes that will play out over time for engineering teams. Either the team will enjoy an upward spiral established by a strong culture of innovation or it will spiral in the downward direction, resulting in an inevitable decay of the team and its products.
Here are my experiences as an engineering leader and how I’ve worked to build a culture around innovation for my teams, virtually at all costs.
The downward spiral
For most engineering teams, it is easy to enter a steady state of development and maintenance as systems get off the ground and mature.
Accordingly, managers often slow or halt hiring as the amount of work is relatively well-understood. As a result, the engineers on the team enter a daily or weekly (or perhaps monthly) ritual of incremental improvements, responding to requests, and fixing bugs.
As engineers churn through task lists, however, they become bored, uninspired, and complacent, resulting in degradation in velocity and/or quality. That degradation will result in more churn around testing and/or support issues, which will further frustrate and bore the engineers while generating more potential for system failures that will increase the churn.
The more churn, the more turnover in staff; the more turnover in staff, the more additional churn. This downward spiral can play out very quickly or it can take quite a while.
In either case, there is a clear direction, it is inevitable, and it has a bad ending.
Upward spiral
The way out of the downward spiral is to make some very difficult decisions that have short-term ramifications for the benefit of the long term. I call this “taking your lumps.”
If you take your lumps now by deferring non-essential work, it frees the team up to think about the long-term and to seek patterns in their work, systems, and operations. Through these patterns, the team can potentially program away a class of work that otherwise would occupy the team’s time on an ongoing basis.
Eliminating a class of work enables the team have more available time in the future to seek other such patterns or opportunities, which will create even more available time.
With the available time, not only is the team further alleviated from the daily churn of reacting to external needs, they are also able to pursue higher order projects that allow the team to make transformative leaps forward rather than churning to keep up or making minor incremental improvements.
Repeated enough, this will eventually become part of the team’s culture, resulting in higher quality work and greater velocity. Unlike the downward spiral, there will positivity around the team that will be infectious and will create a breeding ground for attracting new talent.
Virtually every engineering team will find itself in one of the two aforementioned trajectories. It might not be obvious which way things are headed, but there will be a trend one way or the other.
It is the job of the engineering leader to ensure that the spiral is upward. Here are my 10 philosophies and approaches that I employ with my teams to strive for the upward trajectory:
1. Establish a strong identity
Be very clear on the identity of the team and establish a set of philosophies against which the team can operate. Be stubborn about adhering to the identity. The more that identity gets compromised by one-off requests, the more the architecture weakens, the more churn the team will have to deal with, and the more likely morale will suffer.
Be clear on what you will and won’t do and make sure the team knows these boundaries, lives them, and communicates them to others.
2. Important vs. Urgent
In “The 7 Habits of Highly Effective People,” Stephen R. Covey talks about the difference between urgent and important. Engineering organizations can very easily fall into the trap of being highly reactionary to externally imposed requests.
While many of these externally imposed requests are very important (and in fact, even if they are not), they tend to team’s attention as both urgent and important. But there are many other tasks or efforts that are very important despite the fact that they are internally driven and elective.
Understanding this distinction and being able to distinguish which tasks fall into which category is paramount in getting out of the churn and enabling that first critical step: introspection.
3. Introspection
Introspection is the key to innovation. Handling requests from a range of external (or even internal) stakeholders is the natural, easy thing for a team to do. Taking a step back from those requests and looking for patterns across them while imagining what they might look like in the future will give a broader and more impactful perspective.
If the system gets refactored in some other way, will that eliminate a class of requests in the future? Given how the industry is evolving, can you anticipate weaknesses in the system’s architecture that should be examined now? These are examples of important questions that can help springboard your team out of their everyday churn of satisfying urgent requests.
4. Don’t throw good money at bad
During the introspection process, it is important to be future-oriented. Your team has a lot of functioning code and other system-oriented assets which should be considered.
That said, they should only be considered after evaluating the long-term needs of the team and its relationship to its constituents. Imagine starting from scratch and target that as your outcome. From there, it is much easier to see how, if at all, existing assets can play a role in that future state (or in the transition to get there).
5. Hire beyond your needs
The most important resource to enable introspection is time. Many companies and hiring managers work towards “right-sizing” their teams. That is, they project what the incoming requests will be for the team and attempt to staff the team based on those expectations.
This is perhaps the biggest flaw that a team manager can make when building and operating an innovation team because that will ultimately limit the amount of available time for introspection.
Instead, hiring managers should staff beyond the bandwidth needed for known tasks. This will give the team the ability to swell and contract its focus on such work while continually maintaining a reasonable amount of time towards introspection and innovation.
6. Great engineers NEED to be challenged
If staffing is such that your great engineers are spending the majority of their time handling very tactical work, they will slowly but surely lose interest in the job and eventually leave.
Of course, doing that kind of work is a necessary part of every engineering job, but there needs to be a balance for great engineers to remain happy and excited about their work. Engineers need to also have deep architectural challenges that allow them to think, to stretch their minds, and to have a greater value to the company than just keeping the lights on.
In fact, most of them want to have the freedom to identify and pursue these challenges in a way that help them feel empowered and impactful. That is why engineers get into this field in the first place and if that is not available in their current job for too long, they will find those opportunities elsewhere.
7. Instill a culture of (good) laziness
There are two kinds of “lazy” in engineering: bad laziness and good laziness. Bad laziness is allowing yourself to repeat the same tasks over and over because that is easier than stepping back, looking for patterns, and spending the up-front time to program those tasks away. Manual deployment pipelines or manual tests are great examples. But ultimately, if a human can do it, a computer can (and should) do it too.
This is where good laziness comes in. Great engineers will ultimately be fed up with the arduous nature of the repeated task and seek to eliminate that work from his/her docket.
8. Innovation breeds innovation
Once an initial innovation occurs that liberates the team from some encumbering set of repeated tasks, the team now has some newly available time. That time can be used in any number of ways, but to maximize its utility the team should use that time for even more introspection which paves the way for the upward spiral.
The more such innovations that the team can yield, the more likely the team can yield more innovations. This is the case, not only because of the growth in available time, but also because it eventually becomes part of the team’s culture.
9. Don’t treat your systems like your baby
Many people in the engineering world grow very attached to the systems that they build. It is easy to establish that loyalty as engineers spend a lot of time working on a specific system. In fact, I have often heard people call their systems their baby (I may have been guilty of that in my past as well).
There is a value in growing so attached to the systems in that is does strengthen the bond and builds pride for the team as they strive for excellence with that system. That said, there is a long-term detriment to this as well.
Systems, like virtually any piece of technology, have a limited shelf life. At some point, the system will hit its limit and will need to be overhauled or replaced.
Loyalty to that system clouds one’s objectivity about what is best. We need to be able to treat our solutions as tactics towards a broader goal and if the tactic is no longer effective we need to abandon it.
10. There’s no such thing as maintenance mode
If a system is to go into maintenance mode, it really means one of two things: It is either not an important system anymore (which begs the question as to whether or not it should just be retired outright) or the business function is still important to the company even though the company no longer wants to invest in the system that supports it.
As part of the team’s culture, it is important to aspire to eliminate the idea of maintenance mode from the team’s vernacular.
Maintenance mode has two main detriments. First, it adversely affects the team’s morale and goes against the spirit of great engineers, which is to constantly be challenged. Second, most maintenance systems conflate the idea of supporting a legacy system with supporting its business function.
In fact, the latter is the real goal and an innovative team will seek ways to retire legacy systems in favor of future-oriented systems that still supports the required business function. This is not always easy or feasible, but you should always be seeking opportunities to move on from the legacy system. Sometimes executing on that migration work is of equal or greater value to pursuing new innovations.
External risks
Ultimately, all of these principles depend on having excellent talent on the team. No amount of leadership can offset the challenges introduced by having the wrong skills or people.
Another risk is that many engineers like to chase the shiny new objects. There is a balance that needs to be maintained between enabling great engineers to experiment, innovate, and identify and pursue challenges with their propensity to play with emerging technologies.
It is also worth noting that there are often external forces that prevent some organizations and/or leaders from achieving the above philosophies. For example, not all companies have enough available resources to staff beyond the needs or they may have a legacy of disparate and unrelated technologies that make it inherently more difficult to find a path out of the churn.
As a result, these philosophies require a strong company-level culture that puts leaders and teams in a position to achieve greatness. If the culture is there, however, these 10 philosophies, if truly embraced, will help springboard your team to being innovative and non-reactionary.