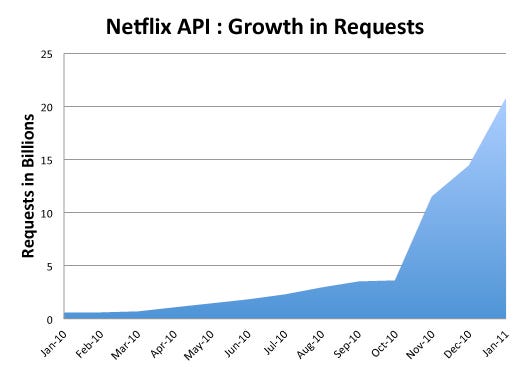
This is Daniel Jacobson, Director of Engineering for the API here at Netflix. The Netflix API launched in 2008 with a focus on the public developer community. The expectation was that this community would build amazing and inspiring applications that would take Netflix to a new level in serving our members. While some fantastic things were built by this community, including sites like Instant Watcher, the transformational moment for the API was when we started to use it to deliver the streaming functionality to Netflix ready devices. In the last year, we have escalated this approach to deliver Netflix metadata through the API to hundreds of devices. All of this has culminated in tremendous growth of the API, as represented by the following chart:
The tremendous growth of the API over the last year is due to a combination of the increased number of users, more activity by our users, Netflix’s steady adoption of new devices over time, as well as chattier interfaces to the API.
Growing the API by about 37× in 13 months indicates a few things to us. First, it demonstrates the tremendous success of the API and the fact that it has become a critical system within Netflix. Moreover, it suggests that, because it is so critical, we have to get it right. When reviewing the founding assumptions of the API from 2008, it is now clear to us that the API needs to be redesigned to carry us into the future.
Establishing New Goals
In the two-and-a-half years that the API has been live, some major, fundamental changes have taken place, both with the API and with Netflix. I already mentioned the change in focus from an exclusively public API to one that also drives our device experiences. Additionally, at the time of the launch, Netflix was primarily focused on delivering DVDs. Today, while DVDs are still part of our identity, the growth of our business is streaming. Moreover, we are no longer US-only. In October, we launched in Canada with a pure streaming plan and we are exploring other international markets as well. Because of these fundamental changes, as well as others that have cropped up along the way, the goals of the API have changed. And because the goals have changed, the way the API needs to operate has as well.
Decreasing Total Requests
An example of where the current design is inefficient is in the way the API resources are modeled. Today, there are about 20 resources in the API. Some of these resources are very similar to each other, although they each have their own interfaces and responses. Because of the number of resources and the fact that we are adhering very closely to the REST conventions, our devices need to make a series of calls to the APIs to get all the content needed to render the user interface. The result is that there is a high degree of chattiness between the devices and the APIs. In fact, one of our device implementations accounts for about 50% of the total API calls. That same device, however, is responsible for significantly less streaming traffic. Why is this device so chatty? Can we design our API to reduce the number of calls needed to create the same experience? In essence, assuming everything remains static, could the 20+ billion requests that we handled in January 2011 have been 15 billion? Or 10 billion?
Decreasing Payload
If we reduce the number of requests to the API to achieve the same user experience, it implies that the payload of each request will need to be larger. While it is possible that this extra payload won’t noticeably impair performance, we still would like to reduce the total number of bits delivered. To do so, we will also be looking at ways to handle partial response through the API. Our goal in this approach will be to conceptualize the API as a database. A database can handle incredible variability in requests through SQL. We want the API to be able to answer questions with the same degree of variability that SQL can for a database. Other implementations, like YQL and OData, offer similar flexibility and we will research them as well. Chattiness and payload size (as well as their impact on the request/response model) are just two examples of the things we are researching in our upcoming API redesign. In the coming weeks, as we get deeper into this work, we will continue to post our thinking to this blog.
If these challenges seem exciting to you, we are hiring! Check out the jobs on the API team at our jobs site.
As I discussed in my recent blog post on ProgrammableWeb.com, Netflix has found substantial limitations in the traditional one-size-fits-all (OSFA) REST API approach. As a result, we have moved to a new, fully customizable API. The basis for our decision is that Netflix’s streaming service is available on more than 800 different device types, almost all of which receive their content from our private APIs. In our experience, we have realized that supporting these myriad device types with an OSFA API, while successful, is not optimal for the API team, the UI teams or Netflix streaming customers. And given that the key audiences for the API are a small group of known developers to which the API team is very close (i.e., mostly internal Netflix UI development teams), we have evolved our API into a platform for API development. Supporting this platform are a few key philosophies, each of which is instrumental in the design of our new system. These philosophies are as follows:
Embrace the Differences of the Devices
Separate Content Gathering from Content Formatting/Delivery
Redefine the Border Between “Client” and “Server”
Distribute Innovation
I will go into more detail below about each of these, including our implementation and what the benefits (and potential detriments) are of this approach. However, each philosophy reflects our top-level goal: to provide whatever is best for the Netflix customer. If we can improve the interaction between the API and our UIs, we have a better chance of making more of our customers happier.
Now, the philosophies…
Embrace the Differences of the Devices
The key driver for this redesigned API is the fact that there are a range of differences across the 800+ device types that we support. Most APIs (including the REST API that Netflix has been using since 2008) treat these devices the same, in a generic way, to make the server-side implementations more efficient. And there is good reason for this approach. Providing an OSFA API allows the API team to maintain a solid contract with a wide range of API consumers because the API team is setting the rules for everyone to follow.
While effective, the problem with the OSFA approach is that its emphasis is to make it convenient for the API provider, not the API consumer. Accordingly, OSFA is ignoring the differences of these devices; the differences that allow us to more optimally take advantage of the rich features offered on each. To give you an idea of these differences, devices may differ on:
Memory capacity or processing power, potentially modifying how much content it can manage at a given time
Requirements for distinct markup formats and broader device proliferation increases the likelihood of this
Document models, some devices may perform better with flatter models, others with more hierarchical
Screen real estate which may impact the content elements that are needed
Document delivery, some performing better with bits streamed across HTTP rather than delivered as a complete document
User interactions, which could influence the metadata fields, delivery method, interaction model, etc.
Our new model is designed to cut against the OSFA paradigm and embrace the differences across devices while supporting those differences equally. To achieve this, our API development platform allows each UI team to create customized endpoints. So the request/response model can be optimized for each team’s UIs to account for unique or divergent device requirements. To support the variability in our request/response model, we need a different kind of architecture, which takes us to the next philosophy…
Separate Content Gathering from Content Formatting/Delivery
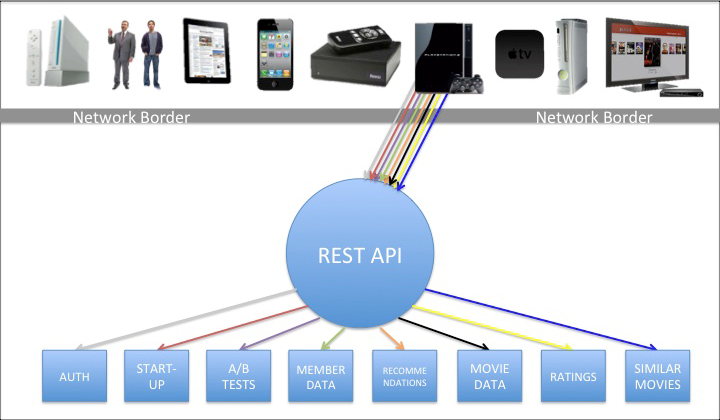
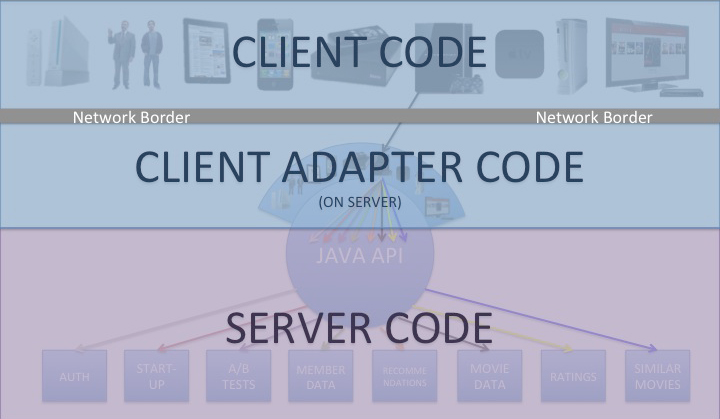
In many OSFA implementations, the API is the engine that retrieves the content from the source(s), prepares that payload, and then ultimately delivers it. Historically, this implementation is also how the Netflix REST API has operated, which is loosely represented by the following image:
The above diagram shows a rainbow of colors roughly representing some of the different requests needed for the PS3, as an example, to start the Netflix experience. Other UIs will have a similar set of interactions against the OSFA REST API given that they are all required by the API to adhere to roughly the same set of rules. Inside the REST API is the engine that performs the gathering, preparation and delivery of the content (indifferent to which UI made the request).
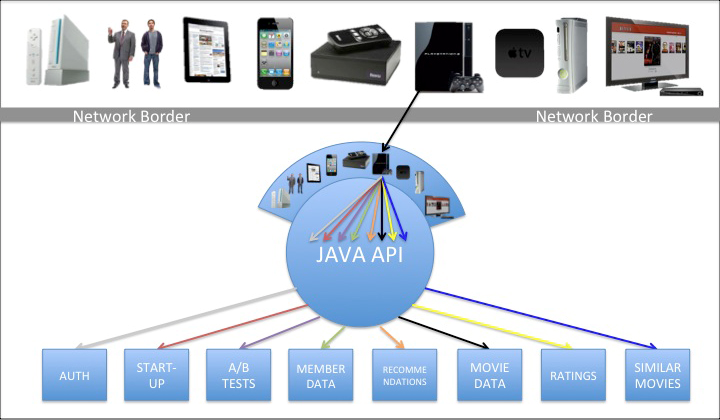
Our new API has departed from the OSFA API model towards one that enables fine-grained customizations without compromising overall system manageability. To achieve this model, our new architecture clearly separates the operations of content gathering from content formatting and delivery. The following diagram represents this modified architecture:
In this new model, the UIs make a single request to a custom endpoint that is designed to specifically handle that request. Behind the endpoint is a handler that parses the request and calls the Java API, which gathers the content by calling back to a range of dependent services. We will discuss in later posts how we do this, particularly in how we parse the requests, trigger calls to dependencies, handle concurrency, support fallbacks, as well as other techniques we use to ensure optimized and accurate gathering of the content. For now, though, I will just say that the content gathering from the Java API is generic and independent of destination, just like the OSFA approach.
After the content has been gathered, however, it is handed off to the formatting and delivery engines which sit on top of the Java API on the server. The diagram represents this layer by showing an array of different devices resting on top of the Java API, each of which corresponds to the custom endpoints for a given UI and/or set of devices. The custom endpoints, as mentioned earlier, support optimized request/response handling for that device, which takes us to the next philosophy…
Redefine the Border Between “Client” and “Server”
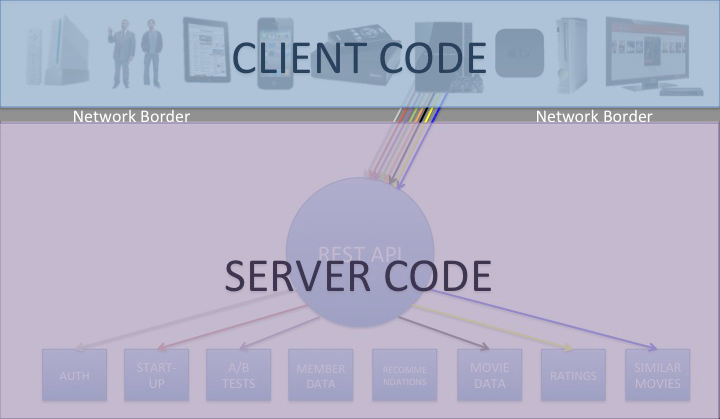
The traditional definition of “client code” is all code that lives on a given device or UI. “Server code” is typically defined as the code that resides on the server. The divide between the two is the network border. This is often the case for REST APIs and that border is where the contract between the API provider and API consumer is engaged, as was the case for Netflix’s REST API, as shown below:
In our new approach, we are pushing this border back to the server, and with it goes a substantial portion of the UI-specific content processing. All of the code on the device is still considered client code, but some client code now resides on the server. In essence, the client code on the device makes a network call back to a dedicated client adapter that resides on the server behind the custom endpoint. Once back on the server, the adapter (currently written in Groovy) explodes that request out to a series of server-side calls that get the corresponding content (in some cases, roughly the same rainbow of requests that would be handled across HTTP in our old REST API). At that point, the Java APIs perform their content gathering functions and deliver the requested content back to the adapter. Once the adapter has some or all of its content, the adapter processes it for delivery, which includes pruning out unwanted fields, error handling and retries, formatting the response, and delivering the document header and body. All of this processing is custom to the specific UI. This new definition of client/server is represented in the following diagram:
There are two major aspects to this change. First, it allows for more efficient interactions between the device and the server since most calls that otherwise would be going across the network can be handled on the server. Of course, network calls are the most expensive part of the transaction, so reducing the number of network requests improves performance, in some cases by several seconds. The second key component leads us to the final (and perhaps most important) philosophy to this approach, which is the distribution of the work for building out the optimized adapters.
Distribute Innovation
One expected critique with this approach is that as we add more devices and build more UIs for A/B and multivariate tests, there will undoubtedly be myriad adapters needed to support all of these distinct request profiles. How can we innovate rapidly and support such a diverse (and growing) set of interactions? It is critical for us to support the custom adapters, but it is equally important for us to maintain a high rate of innovation across these UIs and devices.
As described above, pushing some of the client code back to the servers and providing custom endpoints gives us the opportunity to distribute the API development to the UI teams. We are able to do this because the consumers of this private API are the Netflix UI and device teams. Given that the UI teams can create and modify their own adapter code (potentially without any intervention or involvement from the API team), they can be much more nimble in their development. In other words, as long as the content is available in the Java API, the UI teams can change the code that lives on the device to support the user experience and at the same time change the adapter code to deliver the payload needed for that experience. They are no longer bound by server teams dictating the rules and/or being a bottleneck for their development. API innovation is now in the hands of the UI teams! Moreover, because these adapters are isolated from each other, this approach also diminishes the risk of harming other device implementations with tactical changes in their device-specific APIs.
Of course, one drawback to this is that UI teams are often more skilled in technologies like HTML5, CSS3, JavaScript, etc. In this system, they now need to learn server-side technologies and techniques. So far, however, this has been a relatively small issue, especially since our engineering culture is to hire very strong, senior-level engineers who are adaptable, curious and passionate about learning and implementing these kinds of solutions. Another concern is that because the UI teams are implementing server-side adapters, they have the potential to bring down the servers through infinite loops or other processes that are resource intensive. To offset this, we are working on scrubbing engines that will hopefully minimize the likelihood of such mistakes. That said, in the OSFA world, code on the device can just as easily DDOS the server, it is just potentially a bigger problem if it runs on the server.
Example of how this new system works:
A device, such as the PS3, makes a single request across the network to load the home screen (This code is written and supported by the PS3 UI team.
A Groovy adapter receives and parses the PS3 request (PS3 UI team)
The adapter explodes that one request into many requests that call the Java API to (PS3 UI team)
Each Java API calls back to a dependent service, concurrently when appropriate, to gather the content needed for that sub-request (API team)
In the Java API, if a dependent service unavailable or returns a 4xx or 5xx, the Java API returns a fallback and/or an error code to the adapter (API team)
Successful Java API transactions then return the content back to the adapter when each thread has completed (API team)
The adapter can handle the responses from each thread progressively or all together, depending on how the UI team wants to handle it (PS3 UI team)
The adapter then manipulates the content, retrieves the wanted (and prunes out the unwanted) elements, handle errors, etc. (PS3 UI team)
The adapter formats the response in preparation for delivery back across the network to the PS3, which includes everything needed for the PS3 home screen in the single payload (PS3 UI team)
The adapter finally handles the delivery of the payload across the network (PS3 UI team)
The device will then parse this optimized response and populate the UI (PS3 UI team)
We are still in the early stages of this new system. Some of our devices have fully migrated over to it, others are split between it and the REST API, and others are just getting their feet wet. In upcoming posts, we will share more about the deeper technical aspects of the system, including the way we handle concurrency, how we manage the adapters, the interaction between the adapters and the Java API, our Groovy implementation, error handling, etc. We will also continue to share the evolution of this system as we learn more about it.
This post (originally appearing in ProgrammableWeb.com, which is now defunct) comes from Daniel Jacobson, Director of Application Development for NPR. Daniel leads NPR’s content management solutions, is the creator of the NPR API and is a frequent contributor to the Inside NPR.org blog.
One of the questions that I am most frequently asked regarding content APIs is “how can I make money with my API?” Before answering that question, however, it is important to ask for whom the API is designed. After all, the audiences for your API will determine what business opportunities exist.
The most common target audience for APIs is the developer community. While that audience is an interesting and potentially important one, it is not where the greatest value can be realized.
When we launched the NPR API in 2008, we established four target audiences, each of which were important. The target audiences were (and still are):
NPR: NPR is of highest importance because as we build all of our systems, mobile apps, etc., it was important to be as nimble and efficient as possible. We have adopted this so deeply that the API is the foundation of everything that we do, including acting as the content source to NPR.org.
NPR member stations: NPR member stations are a critical aspect of the NPR mission and business model. Offering the stations a new, more effective way to get NPR content in a robust way better serves the stations and their communities, as well as NPR.
NPR partners: Having the API quickly became a more effective way to interact with content aggregators, business partners and other commercial entities with whom we established relationships. In fact, the API became a business development tool where some external organizations approached us because we had a robust API.
the general public: Finally, as part of our public service mission, it was and is important for NPR to share our content with the world. Exposing it to the developer community is a natural extension of this effort. But when we launched the API, we fully expected this to be where true innovation took place with the API. In fact, the day after our launched, I told CNet that the community of “developers will come up with a lot of brilliant ideas.”
With the API live for a full two years, I decided to look more closely at how effectively the API has been serving these four audiences. Although I am not surprised by the results, you may be…
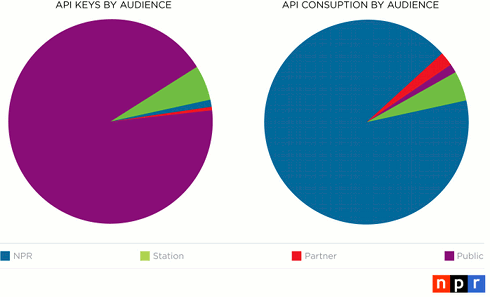
The following charts show the distribution of how many API keys are registered by each of our four audiences. That metric is then compared to the consumption of the API (as measured by API requests) by the four audiences:
Obviously, there are many more API keys registered to the general public than the others. In fact, our API currently has over 10 times more public keys than all other keys in the system combined.
Despite the disparity between public keys and those used by other audiences, the dominant group from a request perspective is overwhelmingly NPR, responsible for more than 92% of the total number of requests. That means that the remaining 8% of requests are coming from all three other target audiences combined.
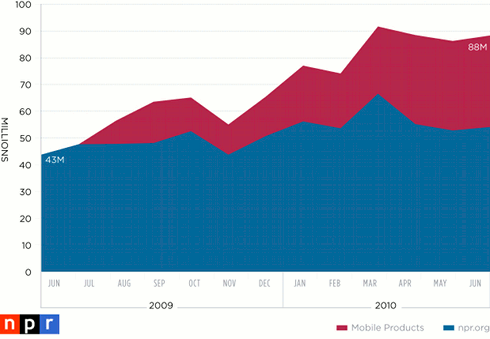
When considering this distribution in requests by audience relative to the key distribution by audience, it is clear that NPR has by far been the most effective user of the API. So, given the incredible amount of consumption by NPR, how has that translated into revenue opportunities? Below is a chart detailing the growth in total page views across all NPR platforms over a twelve-month span:
By the end of the twelve months, NPR’s total page view growth has increased by more than 100%. How were we able to add that many page views in such a short amount of time? The API. Not directly. But the API did enable NPR product owners to quickly, efficiently and independently build specialized apps in various new platforms. As a result, what we have seen is primarily additive growth. In other words, in addition to NPR.org’s growth (by about 19%), we have been able to add the NPR News iPhone app, the improved mobile site, the Android app, the iPad app, etc., each of which adds page views. From our analysis, adding these new platforms is generating new traffic and is not cannibalizing page views from NPR.org in a substantive way. These new page views create new sponsorship/advertising inventory that create new revenue opportunities.
So, when asked the question “how can I make money with my content API?”, the answer should always be based on your target audiences. And from NPR’s experience, the best way to make money is to focus on how the API can improve your internal processes. Of course, it is still important to maintain a solid support and growth model for the other audiences as well, but we cannot all be Google, Netflix, Twitter, etc. Unless you are planning to spend a lot of money on community engagement, you are better served by making sure you can liberate your product owners and grow your business more quickly, efficiently and independently.
In other words, don’t assume that the API’s primary audience is the developer community. Question that default position and do the introspection that will enable you to get the maximum value out of your API.
This article was first published on The Next Web on March 25, 2014
Daniel Jacobson (LinkedIn) is the VP of Edge Engineering for the NetflixAPI. Prior to Netflix, Daniel ran application development for NPR where, among other things, he created the NPR API. He is also the co-author of APIs: A Strategy Guide.
Building great engineering teams is difficult, but it is also increasingly important as the world in which we live is more than ever driven by software. Because of this growing importance, it is essential for engineering leaders to maintain a culture of innovation within their teams to ensure high performance and to keep the company ahead of the curve.
In high performance cultures like at Netflix, there are basically two outcomes that will play out over time for engineering teams. Either the team will enjoy an upward spiral established by a strong culture of innovation or it will spiral in the downward direction, resulting in an inevitable decay of the team and its products.
Here are my experiences as an engineering leader and how I’ve worked to build a culture around innovation for my teams, virtually at all costs.
The downward spiral
For most engineering teams, it is easy to enter a steady state of development and maintenance as systems get off the ground and mature.
Accordingly, managers often slow or halt hiring as the amount of work is relatively well-understood. As a result, the engineers on the team enter a daily or weekly (or perhaps monthly) ritual of incremental improvements, responding to requests, and fixing bugs.
As engineers churn through task lists, however, they become bored, uninspired, and complacent, resulting in degradation in velocity and/or quality. That degradation will result in more churn around testing and/or support issues, which will further frustrate and bore the engineers while generating more potential for system failures that will increase the churn.
The more churn, the more turnover in staff; the more turnover in staff, the more additional churn. This downward spiral can play out very quickly or it can take quite a while.
In either case, there is a clear direction, it is inevitable, and it has a bad ending.
Upward spiral
The way out of the downward spiral is to make some very difficult decisions that have short-term ramifications for the benefit of the long term. I call this “taking your lumps.”
If you take your lumps now by deferring non-essential work, it frees the team up to think about the long-term and to seek patterns in their work, systems, and operations. Through these patterns, the team can potentially program away a class of work that otherwise would occupy the team’s time on an ongoing basis.
Eliminating a class of work enables the team have more available time in the future to seek other such patterns or opportunities, which will create even more available time.
With the available time, not only is the team further alleviated from the daily churn of reacting to external needs, they are also able to pursue higher order projects that allow the team to make transformative leaps forward rather than churning to keep up or making minor incremental improvements.
Repeated enough, this will eventually become part of the team’s culture, resulting in higher quality work and greater velocity. Unlike the downward spiral, there will positivity around the team that will be infectious and will create a breeding ground for attracting new talent.
Virtually every engineering team will find itself in one of the two aforementioned trajectories. It might not be obvious which way things are headed, but there will be a trend one way or the other.
It is the job of the engineering leader to ensure that the spiral is upward. Here are my 10 philosophies and approaches that I employ with my teams to strive for the upward trajectory:
1. Establish a strong identity
Be very clear on the identity of the team and establish a set of philosophies against which the team can operate. Be stubborn about adhering to the identity. The more that identity gets compromised by one-off requests, the more the architecture weakens, the more churn the team will have to deal with, and the more likely morale will suffer.
Be clear on what you will and won’t do and make sure the team knows these boundaries, lives them, and communicates them to others.
2. Important vs. Urgent
In “The 7 Habits of Highly Effective People,” Stephen R. Covey talks about the difference between urgent and important. Engineering organizations can very easily fall into the trap of being highly reactionary to externally imposed requests.
While many of these externally imposed requests are very important (and in fact, even if they are not), they tend to team’s attention as both urgent and important. But there are many other tasks or efforts that are very important despite the fact that they are internally driven and elective.
Understanding this distinction and being able to distinguish which tasks fall into which category is paramount in getting out of the churn and enabling that first critical step: introspection.
3. Introspection
Introspection is the key to innovation. Handling requests from a range of external (or even internal) stakeholders is the natural, easy thing for a team to do. Taking a step back from those requests and looking for patterns across them while imagining what they might look like in the future will give a broader and more impactful perspective.
If the system gets refactored in some other way, will that eliminate a class of requests in the future? Given how the industry is evolving, can you anticipate weaknesses in the system’s architecture that should be examined now? These are examples of important questions that can help springboard your team out of their everyday churn of satisfying urgent requests.
4. Don’t throw good money at bad
During the introspection process, it is important to be future-oriented. Your team has a lot of functioning code and other system-oriented assets which should be considered.
That said, they should only be considered after evaluating the long-term needs of the team and its relationship to its constituents. Imagine starting from scratch and target that as your outcome. From there, it is much easier to see how, if at all, existing assets can play a role in that future state (or in the transition to get there).
5. Hire beyond your needs
The most important resource to enable introspection is time. Many companies and hiring managers work towards “right-sizing” their teams. That is, they project what the incoming requests will be for the team and attempt to staff the team based on those expectations.
This is perhaps the biggest flaw that a team manager can make when building and operating an innovation team because that will ultimately limit the amount of available time for introspection.
Instead, hiring managers should staff beyond the bandwidth needed for known tasks. This will give the team the ability to swell and contract its focus on such work while continually maintaining a reasonable amount of time towards introspection and innovation.
6. Great engineers NEED to be challenged
If staffing is such that your great engineers are spending the majority of their time handling very tactical work, they will slowly but surely lose interest in the job and eventually leave.
Of course, doing that kind of work is a necessary part of every engineering job, but there needs to be a balance for great engineers to remain happy and excited about their work. Engineers need to also have deep architectural challenges that allow them to think, to stretch their minds, and to have a greater value to the company than just keeping the lights on.
In fact, most of them want to have the freedom to identify and pursue these challenges in a way that help them feel empowered and impactful. That is why engineers get into this field in the first place and if that is not available in their current job for too long, they will find those opportunities elsewhere.
7. Instill a culture of (good) laziness
There are two kinds of “lazy” in engineering: bad laziness and good laziness. Bad laziness is allowing yourself to repeat the same tasks over and over because that is easier than stepping back, looking for patterns, and spending the up-front time to program those tasks away. Manual deployment pipelines or manual tests are great examples. But ultimately, if a human can do it, a computer can (and should) do it too.
This is where good laziness comes in. Great engineers will ultimately be fed up with the arduous nature of the repeated task and seek to eliminate that work from his/her docket.
8. Innovation breeds innovation
Once an initial innovation occurs that liberates the team from some encumbering set of repeated tasks, the team now has some newly available time. That time can be used in any number of ways, but to maximize its utility the team should use that time for even more introspection which paves the way for the upward spiral.
The more such innovations that the team can yield, the more likely the team can yield more innovations. This is the case, not only because of the growth in available time, but also because it eventually becomes part of the team’s culture.
9. Don’t treat your systems like your baby
Many people in the engineering world grow very attached to the systems that they build. It is easy to establish that loyalty as engineers spend a lot of time working on a specific system. In fact, I have often heard people call their systems their baby (I may have been guilty of that in my past as well).
There is a value in growing so attached to the systems in that is does strengthen the bond and builds pride for the team as they strive for excellence with that system. That said, there is a long-term detriment to this as well.
Systems, like virtually any piece of technology, have a limited shelf life. At some point, the system will hit its limit and will need to be overhauled or replaced.
Loyalty to that system clouds one’s objectivity about what is best. We need to be able to treat our solutions as tactics towards a broader goal and if the tactic is no longer effective we need to abandon it.
10. There’s no such thing as maintenance mode
If a system is to go into maintenance mode, it really means one of two things: It is either not an important system anymore (which begs the question as to whether or not it should just be retired outright) or the business function is still important to the company even though the company no longer wants to invest in the system that supports it.
As part of the team’s culture, it is important to aspire to eliminate the idea of maintenance mode from the team’s vernacular.
Maintenance mode has two main detriments. First, it adversely affects the team’s morale and goes against the spirit of great engineers, which is to constantly be challenged. Second, most maintenance systems conflate the idea of supporting a legacy system with supporting its business function.
In fact, the latter is the real goal and an innovative team will seek ways to retire legacy systems in favor of future-oriented systems that still supports the required business function. This is not always easy or feasible, but you should always be seeking opportunities to move on from the legacy system. Sometimes executing on that migration work is of equal or greater value to pursuing new innovations.
External risks
Ultimately, all of these principles depend on having excellent talent on the team. No amount of leadership can offset the challenges introduced by having the wrong skills or people.
Another risk is that many engineers like to chase the shiny new objects. There is a balance that needs to be maintained between enabling great engineers to experiment, innovate, and identify and pursue challenges with their propensity to play with emerging technologies.
It is also worth noting that there are often external forces that prevent some organizations and/or leaders from achieving the above philosophies. For example, not all companies have enough available resources to staff beyond the needs or they may have a legacy of disparate and unrelated technologies that make it inherently more difficult to find a path out of the churn.
As a result, these philosophies require a strong company-level culture that puts leaders and teams in a position to achieve greatness. If the culture is there, however, these 10 philosophies, if truly embraced, will help springboard your team to being innovative and non-reactionary.
The digital world is expanding at an amazing rate, giving us access to applications and content on myriad connected devices in your homes, offices, cars, pockets and on even on your body. The glue that allows all of this to happen, that connect the companies who provide these services to the devices that you use, is the API.
Because APIs have such a huge responsibility for so many people and companies, it is natural that API design is often one of the industry’s liveliest discussions, touching on a range of topics including resource modeling, payload format, how to version the system, and security.
While these are likely important areas to explore when designing virtually any API, the reality is that a much larger decision needs to be made first. That decision is based on a fundamental question: who are the primary audiences for this API and how can we optimize for those audiences?
This seems like an innocuous enough question, but don’t underestimate its importance or complexity in the growing world of APIs.
Years ago, this question was much simpler
At that time, many emerging APIs were being built as open or public APIs, targeting a large set of unknown developers (LSUDs) external to the providing company.
In a previous post, I referred to these as OSFA APIs (or one-size-fits-all APIs). Allowing for such granularity in the modeling means that any developer who wishes to use the API can mix and match the elements in whatever way they choose to satisfy their application without further API team involvement.
The resource-model approach to designing an API can be very powerful, especially for this type of audience. The problem with this approach, however, is that the way that many companies use APIs today is different than described above. While many are still supporting the use cases of LSUDs, more are using their APIs to support a growing mobile or device strategy.
For some of these implementations, the engagement with the developers is different. The audience is a small set of known developers (SSKDs). They may be engineers down the hall from the API team, a contracted company hired to develop an iPhone app, or an engineering team in a partnering company. In all of these cases, however, the API team knows who these people are (at least in the abstract sense).
More importantly, however, the API team and the providing company care about the success of these implementations in a different way than they might care about the applications developed by the LSUDs. In fact, the success of the SSKDs may very well be paramount to the success of the business as a whole, a model that is becoming increasingly more pervasive.
Because of this change in audience and the deep interest in their success, there is great opportunity to change the API design.
For the SSKDs, having granular resource-based APIs that closely represent the data model works, but it just isn’t as optimal as it could be. This is especially the case when you consider the growing number of device types in the world and the fact that more and more companies’ business strategies are dependent on providing value to customers on such devices.
So, all it takes is a couple of devices with diverging needs and/or capabilities, each of great import to the company, for the resource-based API to start to show some warts. Making the API better, more optimized, for each of these target applications is the next logical, and most critical, step.
Enter the Orchestration Layer
An API Orchestration Layer (OL) is an abstraction layer that takes generically-modeled data elements and/or features and prepares them in a more specific way for a targeted developer or application
To address this opportunity, more companies are employing orchestration layers into their API infrastructure. While there are many ways in which to implement this architectural construct, the concept remains the same across all of them.
Below, I will describe a few of the more common patterns that I have seen (and/or been involved in implementing). But first, here are a few key principles that need to be considered when building an OL:
1. Most APIs are designed by the API provider with the goal of maintaining data model purity. When building an OL, be prepared to sometimes abandon purity in favor of optimizations and/or performance.
2. Many APIs are designed by API teams to make it easier for the API team to support. When building an OL, be prepared to potentially add complexity for the API team (or other teams, depending on the way it is implemented).
While this sounds undesirable, the goal here is to dramatically improve efficiency and/or simplicity for other people at some mild cost to the API team. Also keep in mind that such costs can potentially be programmed away over time.
3. It is important to understand the breadth of the audiences for the API.Depending on those constituents, you may only need the OL. In other cases, you may need the OSFA foundation in addition to the OL.
Here are a few examples of how some OLs have been approached:
Device-specific wrappers
This is the most common pattern that I have seen because most companies that are experiencing the distress referenced above already have APIs that they still use, continue to support, and invest in. The result is to continue to offer the granular resources as they always have, but to offer a wrapper tier on top of them – with new endpoints that are tailored to specific developers, devices or device clusters.
In this model, the API team will work more closely with, for example, the iPhone team to write a custom wrapper that handles specific requests and deliver specific payloads that are optimized for the iPhone app. In this model, most often the team to build the endpoints and the wrappers is the API team although that doesn’t have to be the case.
Query-based APIs
In this model, the API team is putting the power in the hands of the requesting developer, although that power is limited. The goal here is to create a more flexible way in which the requester can make requests and tailor payloads without putting additional ongoing burden on the API team, as could be the case with the Device-Specific Wrappers.
This is achieved by breaking down the resource-based APIs and allowing them to be queried against like a database through flexible parameters and payloads that can contract, expand and possibly morph based on what is needed. The benefit here is that once the query language is set, the API team does not need to keep writing wrappers as new implementations are needed for different devices.
The detriment, however, is that the query-based API is still a set of rules to which the developer needs to adhere, although these rules are much more flexible than the resource-based API model.
Experienced-based APIs
This is the model that Netflix has implemented, which in some ways is a blend of the two above. In this model, we basically have device-specific wrappers but they are designed, implemented and owned by the device teams.
A key concept here is that we have put the API team in the position of gathering the data in a generic, reusable way while putting the device teams in the position of owning the data formatting and delivery. After all, the formatting needs evolve in concert with the UI changes so putting that effort in the hands of those closest to the changes eliminates additional steps.
(For more details on how this system operates, see the links at the bottom of the post.)
As I noted, the range of implementations is potentially much more diverse than these three, although these are some of the most consistent and interesting patterns that I have seen. Regardless of how this is achieved, however, the key is for the API team to stop supporting the API as a service that is designed independent of those SSKDs who consume it.
Rather, the API team needs to view the SSKDs as partners in the design with an interest in making the products as great as possible so the end-users can get the best experience possible. The API team has the opportunity to build services that help developers to be better at developing by focusing on optimizing for the developers’ needs rather than how to optimize the time spent supporting the API.
“Strategy without tactics is the slowest route to victory. Tactics without strategy is the noise before defeat.” – Sun Tzu, The Art of War
Over the course of 2013, the API industry has matured a great deal. Not only have we seen many of the major vendors (ie. Apigee, Mashery, 3Scale, Layer7, etc) get acquired and/or receive large rounds of funding, we are also seeing an uptick in new players, new tools and services, new publications, and even a series of API-focused conferences.
Meanwhile, according to a recent survey by Layer7, more than 85% of companies expect to have an “API program” within the next five years. All of this is evidence that the appetite for tools and information about APIs is robust. Accordingly, there is no shortage of people and companies attempting to satisfy that hunger. The question I have amidst this growth, however, is whether the concepts around API strategies being served by some is the right meal for those who are eager to feast on APIs.
The problem: “API Strategy”
The majority of the non-technical conversations in the API industry seem to be focusing on terms like “API strategy” and “API economy.” In fact, I even co-wrote a book called APIs: A Strategy Guide a couple of years ago, further facilitating the use of those words in the API vernacular. There is absolutely a strong case to be made for needing an API strategy for certain situations. But how many companies should really be thinking about their API in that way?
Before continuing, it is worth being clear on what I mean by the terms “strategy” and “tactic”. Bobby Ghoshal puts it nicely in his post, Greeks Gave us Strategy vs. Tactics: Now Understand the Difference where he says, “A strategy is a grand plan, a tactic is a specific measure implemented to push the grand plan forward.” Applied to APIs, if there is an API strategy then it means that API is the product in-and-of-itself. In other words, the API is the target of a distinct business and opportunity (with its own metrics), which will then have a range of tactics to support it.
There are certainly cases where APIs are businesses and where a strategy is appropriate. The most common example of an API strategy is around companies who aspire to build a developer community as a new revenue source or as the foundation of their business. Twilio is an interesting example of such a company. Twilio’s strategy is to offer APIs that tap into their backend services to allow developers to build apps supporting their communication initiatives.
In this case, the API is a strategy, one that is fundamental to the business as a whole. Accordingly, Twilio invests heavily in the API, supporting documentation for it, fostering the developer community, and all of the other things one would expect such a company to do for their public API (and some would suggest that they do this as well as or better than anyone else). Twilio should invest heavily in this — a significant portion of the opportunity is predicated on the success of the API program.
The reality: “API as a tactic”
But most companies should not be trying to set up distinct businesses with their APIs as the focal point. They should not be trying to generate new revenue streams or reach new audiences through such programs. Instead, most companies should be focusing on their core business and then designing APIs that support larger strategy.
In pursuing that route, most companies should not be discussing their “API Strategy,” they should be talking about their API as a tactic in support of their broader business strategy and objectives.
An example that I am very close to is Netflix. In the early days of the Netflix API when the program was targeted exclusively to public developers, the API had its own metrics and its own objectives, all of which were designed to support the primary goals of the company.
In this sense, the Netflix API was a product designed to offer incentives to developers to motivate them to build applications around the Netflix experience. These applications would hopefully reach new audiences to generate new subscribers and/or create new user experiences for existing subscribers that would increase their satisfaction with our service. Although the API was treated as a new product within Netflix, it was still operating under the company’s larger business objectives.
While the original vision was incrementally valuable to the company, the results were not as transformative as originally expected. As a result, we pursued a new approach with the API, using it to drive the larger strategy of device proliferation for our growing streaming business. In this sense, the API was transitioning from a product to a tactic.
Today, Netflix can be watched on more than 1,000 different device types, the vast majority of which are developed by Netflix-employed UI Engineers. The API served as an excellent engineering tactic that allowed us to quickly get on more devices, which in turn allows us to create a better overall experience for our customers.
More changes have since been made with the API. Most recently, the Netflix API team, which used to provide traditional REST APIs to the Netflix UI teams, is now providing content distribution platforms that enable data to be pushed from our AWS backend systems to the devices in people’s homes and pockets. We are no longer truly an API team, we are a team that embraces the differences of the different devices and empowers the UI teams to customize and optimize the request/response models needed for their specific device. In other words, we are now a platform for API development.
All of these pivots within Netflix further demonstrate that our API is nothing more than a tactic to achieve our broader goals. There are no allegiances to a tactical solution. Tactics can (and should) be modified, discarded and replaced as appropriate. Strategies, on the other hand, should have longer shelf-lives, evolving over time but less frequently overhauled.
The majority of companies that are considering API implementations, based on my conversations and experience in the industry, are more like Netflix than Twilio. There are countless examples of companies who have made similar pivots to refocus their API attention towards supporting the company’s primary business objectives. These examples range from media companies (NPR, The New York Times, The Guardian) to financial institutions (PayPal, E-Trade) to social media sites (Twitter, LinkedIn).
Even service companies like Amazon and Salesforce, whose systems are differentiated in part by their APIs, use them as a tactic to provide increased value for the primary business, which is providing robust services supporting cloud computing and CRM respectively.
The bottom line
The key to a successful API program is to know your audience. Your audience is defined by your business opportunity. So, be very thoughtful about the opportunity and then define your API accordingly. In some cases, pursuing the public developer opportunity is absolutely the right thing to do and it may have a tremendous upside (although realizing that upside is quite rare).
However, if your opportunity is truly to support a broader business objective, then launching a public developer program is not likely to yield large dividends. It is more likely to come with increased costs and risks that will weigh down your returns, dilute your resources for the larger opportunity, and distract you from the real prize. Instead, focus all of your energy on building a great system that helps you optimize for the larger goal. And don’t be married to that system as it is nothing more than a tactic.
Ultimately, if you know your audience, you can define a strategy and then design the right tactics. Otherwise, brace yourself for a very slow route to victory or, more likely, a noisy defeat.
This post originally appeared on The Next Web on September 15, 2013.
Congratulations again to Kin Lane and everyone at 3Scale for a very successful and fulfilling API Strategy Conference. There were a lot of great presentations and panels as well a many very interesting hallway conversations.
And I was exited to be able to speak at the event! Embedded below are the slides from my presentation, complete with copious notes on each slide to provide the context of what I said during the talk.
The focus of the presentation was on API revolutions. We have seen a number of them in the recent years, but there have been significant and substantial changes for Netflix and for some others that warrant discussion. The question that remains is: Are these changes specific to a small handful of companies or are these companies representing things to come for the API world as a whole?
Last Friday (February 8th), I spoke at the Intelligent Content Conference 2013. When Scott Abel (aka The Content Wrangler) first contacted me to speak at the event, he asked me to speak about my content management and distribution experiences from both NPR and Netflix. The two experiences seemed to him to be an interesting blend for the conference. And when I got to the conference, I was absolutely floored by the number of people who had already heard about NPR’s COPE model!
I have to admit, it had been a while since I last thought that much about the NPR days, but doing so brought back a lot of interesting memories. When more deeply considering those experiences alongside my Netflix experience, I was able to see commonalities in practice, philosophy, execution and results (although at different scales).
At any rate, embedded below are the slides from my presentation. I spent a good chunk of time commenting each slide as my presentations tend to be very image-heavy, which often results in lost context. The comments have added that context back in.
Thanks again, Scott, for having me at the conference. And thanks to all of the attendees with whom I spoke before and after my talk. The event was a lot of fun!
With respect to Web APIs, the industry has clearly and emphatically landed on REST as the standard way to implement these services. And for good reason… REST, which is generally implemented as a one-size-fits-all solution, is an excellent choice for a most companies who wish to expose their content to third parties, mobile app developers, partners, internal teams, etc. There are many tomes about what REST is and how best to implement it, so I won’t go into detail here. But if I were to sum up the value proposition to these companies of the traditional REST solution, I would describe it as:
REST APIs are excellent at handling requests in a generic way, establishing a set of rules that allow a large number of known and unknown developers to easily consume the services that the API offers.
In this model, everyone knows how to behave and it can be incredibly powerful. The API providers establish a set of rules and the API consumers must adhere to those rules to get what they want from the API. It is perfect, right? In many cases, the answer is obviously yes. But in other cases, as our world scales and the number of ways for people to consume digital content and services continues to expand, this one-size-fits-all model is likely to fall short.
The potential shortcomings surface because this model assumes that a key goal of these APIs is to serve a large number of known and unknown developers. The more I talk to people about APIs, however, the clearer it is that public APIs are waning in popularity and business opportunity and that the internal use case is the wave of the future. There are books, articles and case studiescropping up almost daily supporting this view. And while my company, Netflix, may be an outlier because of the scale in which we operate, I believe that we are an interesting model of how things are evolving.
Netflix is currently available on over 800 different device types, including game consoles, mobile phones, TVs, Blu-ray players, tablets, computers, and almost any other device that can stream video. Our API alone handles more than two billion incoming requests on peak days, which translates into almost ten billion real-time outgoing requests from the API to internal dependency services. These numbers are up by about 70x from just two years ago. Most companies do not have that kind of scale, but it is clear that with the continued growth of the device market more companies are resetting their strategies to be less about the public API and more about internal consumption of their own APIs to support device proliferation. When this transition occurs, the API is no longer targeting “a large number of known and unknown developers.” Rather, the key audience is a small number of known developers.
The potential conflict between the internal and public use cases is in the design of the API itself. Keep in mind that the design implications will not be problematic in many scenarios. It becomes a potential problem if the breadth of devices becomes so wide that the variability of features across them becomes substantially harder to manage. It is the breadth of devices that creates a problem for the one-size-fits-all API solutions.
If your target is a small group of teams with whom you have close relationships, the dynamics around the API change. For Netflix, we persisted on the one-size-fits-all REST model for quite a while as more and more devices got added on top of the API. But given our scale, one thing has become increasingly obvious. Our REST API, while very capable of handling the requests from our devices in a generic way, is optimized for none of them. This is the case because our REST API focuses on resources that are meant to be granular representations of the data, from the perspective of the data. The granularity is exactly what allows the API to support a large number of known and unknown developers. Because it sets the rules for how to interface with the data, it also forces all of the developers to adhere to those rules. That means that each device potentially has to work a little harder (or sometimes a lot harder) to get the data needed to create great user experiences because devices are different from each other.
The differences across these devices can be varied and sometimes significant. Here are some examples of variances across devices that may be challenging for one-size-fits-all models:
Different devices may have different memory capacity
Some devices may require a unique or proprietary format or delivery method
Some devices may perform better with a flatter or more hierarchical document model
Different devices have different screen real estate sizes which may impact which data elements are needed
Some devices may perform better having bits streamed across HTTP rather than delivered as a complete document
Different devices allow for different user interaction models, which could influence the metadata fields, delivery method, interaction model, etc.
Just think about the differences between an iPhone and your TV and how they beg for different user experiences. Moreover, the XBox and the Wii, both of which project to the TV, are different in the way users interact with them as well as in the hardware constraints, both of which may require different APIs to support them. When considering more than 800 different device types, the variance across them becomes overwhelming. And as more manufacturers continue to innovate on these devices, the variance may only broaden.
How do you know if your company is ready to consider alternatives to the one-size-fits-all API model? Here are the ingredients needed to help you make that decision:
Small number of targeted API consumers is the top priority
Very close relationships between these API consumers and the API team
An increasing divergence of needs across the top priority API consumers
Strong desire by the API consumers for more optimized interactions with the API
High value proposition for the company providing the API to make these API consumers as effective as possible
If these ingredients are met, then you have the recipe for needing a new kind of API.
Because of the differences in these devices, Netflix UI teams would often have to do a range of things to get around our REST API to better serve the users of the device. Sometimes, the API team would be required to extend the base service to handle special cases, often resulting in spaghetti code or undocumented features. And because different teams have different needs, in the REST API world, we would often need to delay feature development for some due to the challenges around prioritization. In addition to these kinds of issues, significant performance and/or architectural problems are bound to emerge. For example, these more granular APIs often result in chattier interactions between device and server or chunkier payloads, as I discussed in a previous post on the Netflix Tech Blog.
To solve this issue, it is becoming increasingly common for companies (including Netflix) to think about the interaction model in a different way. Rather than having the API create a set of rather rigid rules and forcing the various devices to follow them, companies are now thinking about ways to let the UI have more control in dictating what is needed from a service in support of their needs. Some are creating custom REST-based APIs to support a specific device or category of devices. Others are thinking about greater granularity in REST resources with more batching of calls. Some are creating orchestration layers, such as ql.io, in their API system to customize the interaction. These are all smart and practical ways around the problem. But with the growing number of devices, the increasing urge for companies to be on as many of them as possible, and the desire for continued innovation across these devices, these various solutions are still somewhat restricted. They are still forcing the developers to adhere to server-side rules and non-optimized payloads in an effort to have a one-size-fits-all solution. These approaches are closer to the flexibility needed in that they are not as rigid as the typical REST-based solution, but when supporting as many devices as Netflix does, we believe they fall short for us.
For Netflix, our goal is to take advantage of the differences of these devices rather than treating them generically. As a result, we are handing over the creation of the rules to the developers who consume the API rather than forcing them to adhere to a generic set of rules applied by the API team. In other words, we have created a platform for API development.
The purpose of a content API is to make the content available to its audience in the most useful and efficient way possible. To be a useful API, it needs to help the developers make their jobs easier. This could mean a wide range of things, including making it easier to dig into the API, allowing for greater flexibility in the responses, improved performance and efficiency for both the API and its consumer. Below are seven development techniques (all of which are part of the NPR API) that can help content providers improve the usefulness and efficiency of their APIs on both sides of the track. These techniques played a critical role in the success of the API which now delivers over 700 million stories per month to its users (more stats on the NPR API coming soon on our Inside NPR.org blog).
Be Flexible: Support Multiple Output Formats
Making the API as available and accessible as possible is very important in drawing developers to use it. So providing the content in a range of formats will increase the likelihood that the developer can rely on existing libraries and make as few changes to the code as possible.
The NPR API offers eight different output formats in an effort to improve efficiency for the developers. Above is a graph demonstrating the distribution of requests for each of the formats in July of 2009. As you can see, the majority of requests are to our proprietary XML markup (NPRML). That also means that almost 50% of the requests, or about 20M requests per month, use the other seven formats. In offering offering these other non-proprietary XML formats, the API is able to support developers that may have existing applications that pull in content in one of these standardized format, such as MediaRSS or Atom.
To make it even easier for people to use the API, NPR also launched with JavaScript and HTML “widgets”. The other six formats require more sophistication in order to put the content in an application or website. The widgets, however, are pre-designed feeds of NPR content (based on the developer’s selections) that can be easily dropped into a page.
Be Efficient: Handle Partial Response
This concept is now starting to get some more traction, now that Google announced partial response handling for some of their APIs. NPR’s API also makes extensive us of this feature because it really is tremendously valuable to the provider and the consumer of the API. For example, NPR stories contain a wide variety of fields and assets in the API. If the consumer is forced to handle the complete document, even if they only want a few fields, they have to endure all of the latency issues from the API itself as well as the additional processing power needed to handle the undesired fields.
As a result, NPR incorporated a “fields” parameter (the same parameter name used by Google) that can be used in the query string to limit the resulting document to only the fields of interest. This approach creates documents that are smaller and much more efficient. Overwhelmingly, more requests to the NPR API contain the fields parameter than those that do not (in fact, it isn’t even close).
Here are a few examples of how the same query to the NPR API, returning the same stories, delivers different documents based on the fields parameter (you will need to register for your own NPR API key to execute these queries):
An extension of partial response is to allow the developer to specify the number of items they would like in return. Some APIs return a fixed number of results, which can bloat the document just like the extra fields can. The NPR API, to counter this, allows the developer to pass in the number of results desired (with a fixed ceiling for any given request). To dig deeper in the results, we incorporated a “pagination” feature in the API. Here are some examples of how to control the number of stories:
Give Them Control: Allow for Customizable Output Markup (“Remapping Fields”)
As mentioned in the transform section, if the API can easily serve existing applications that expect specific markup, it potentially increases adoption and improves developer efficiency. To extend that functionality, the NPR API offers a function that we call “Remap” which essentially lets the developer modify the name of one or more XML elements or attributes in the output at request time. This is done in the query string and the API transforms the markup accordingly in real-time. Here are a few examples:
In this example, the remap parameter changes the story title to < specialTitle >:
Another benefit to remap (which we have fortunately not had to use) is that it can be used to handle backward compatibility as the API grows and changes. NPR’s philosophy is to make sure that upgrades do not adversely affect existing functionality. That said, if an element or attribute does need to change, we could execute apache rewrites for all old API calls and have the remap function applied to have the output match that of the old markup. Alternatively, the developer could simply modify their API call instead of having to change their codebase to match the markup changes. (Although we do not intend to change existing markup, if we do, we would advise developers to upgrade their code accordingly. That said, rather than having the applications fail during the transition, remap could be used to temporarily handle requests until the full codebase can be upgraded).
Be Fast: Set Up a Comprehensive Caching Architecture
Performance is another critical aspect of APIs when it comes to enticing developers to use them. After all, if the API is sluggish, developers may not want to depend their application on it.
Smart caching of queries and results can really improve the speed of the system. NPR has implemented several layers of caching for the API, as follows:
Base XML – Caching the full document for each item is important to prevent the system from executing disk I/O before doing any transform. We cache the Base XML first in memory and secondarily as XML files to eliminate the need to access our content database.
Full Query Results – When compiling the list of items to be returned for any given story, it is important to cache the full list because popular applications that have many concurrent users (such as NPR Addict) are very likely to execute the same queries and expect the same results. The cached result is a single document containing the full list of all items and the full base XML for each.
Transformed Query Results – The calling application, such as NPR Addict, expects the document to be transformed to fit the application’s needs. So, the results that get cached in Full Query Results may get transformed to MediaRSS while simultaneously removing extraneous fields. Caching the final results that get returned to the calling application enable fastest performance without compromising the system’s ability to use the other caching layers to produce different versions of the document.
Give Them Tools: Provide a Query UI with the Documentation
There are two truths about developers and documentation: the former always expects the latter, but seldom uses it. Of course, you cannot have an API without providing comprehensive documentation. That said, offering a simple user interface that helps developers get what they need from the API wil increase adoption and make life easier for them.
NPR’s API launched with a tool that we call the Query Generator. This tool exposes more than 6500 query-able IDs, methods for controlling the output format, fields to be returned, date and search restrictions, pagination, and more. Using the interface, the developer can select their options and have the tool create the query string for their API request. The developer can also see the results of that query inline before commiting it to their application. Almost exclusively, developers (including the NPR staff) use this tool to create queries, rather than reading the documentation.
Be Open: Eliminate Rate Limiting
Throttling or limiting access to APIs is an inherent disincentive for developers. Moreover, it is actually a detriment to the API provider. After all, the purpose of the API is to grant access to the content. If a given developer can only call the API 5000 times a day, and that developer creates a hugely popular application, the rate-limiting will inherently stifle the developer and the viral nature of the API.
Granted, most APIs use rate-limiting or tiered access levels to allow business people to control the graduation of API users. This seems counter-productive to me though. The better approach is to open access completely, identify those incredibly successful usages, then work with the developer accordingly on a mutually beneficial relationship. This way, applications are given full ability to grow and mature without arbitrary constraints.
Other APIs implement rate-limiting to protect the servers from unexpectedly high load. This is a legitimate risk which, if encountered, can adversely affect the performance of all users. That said, building complicated features into the system, such as rate-limiting, can be much more costly than configuring a scalable server architecture. Moreover, each request to the API will see slight latency increases as a result of the rate-limiting analysis. I know that latency is marginal, but why introduce any additional latency, especially when creating disincentives for developers?
Be Agile: Practice Iterative Development
Building your API over time has several benefits. First, it signals to the developer community that this API is meaningful to the provider and will continue to grow and get supported over time. This sounds trivial, but it is a very important part of the relationship with the community. If developers are not sure about your commitment to the API, are they likely to spend their own time building an application around it?
Another benefit of iterative development is that you do not have to get the API perfect the first time. I will qualify that by saying that, as a matter of principle, any release for an API should be done with the expectation that it will be supported for a long time. This is important because changes to existing API features will break the applications of those that use them. When I say the API doesn’t have to be perfect, I mean it does not have to be complete. New features can (and should) be added over time, extending its capability and making it more attractive for potential developers.
To put it another way, you will not have every detail of the API solved at the initial launch. It is much better to go live with the features that you know well while deferring those that you do not. Trying to cram in tenuous requirements will create headaches for you and for the community down the road. Spend the time necessary on figuring out the features, the supporting markup, the access and error methods, etc. before you commit to an API feature.







{kind=link}